Pedro Miraldo

- Phone: 617-621-7536
- Email:
-
Position:
Research / Technical Staff
Senior Principal Research Scientist -
Education:
Ph.D., University of Coimbra, 2013 -
Research Areas:
External Links:
Pedro's Quick Links
-
Biography
Pedro Miraldo held an FCT postdoctoral researcher grant at the Institute for Systems & Robotics and the Department of Electrical & Computer Engineering, IST Instituto Superior Tecnico Lisbon from 2014 to 2018. Then, he joined the Division of Decision and Control Systems at KTH Royal Institute of Technology as a postdoctoral associate from 2018 to 2019. Finally, he returned to IST in 2019 as a second-stage Researcher (comparable to Assistant Research Professor).
-
Recent News & Events
-
NEWS MERL Presents 7 Papers and 2 Workshops at CVPR 2026 Date: June 3, 2026 - June 7, 2026
Where: Colorado Convention Center, Denver, Colorado
MERL Contacts: Moitreya Chatterjee; Anoop Cherian; Kaen Kogashi; Suhas Lohit; Lalit Manam; Tim K. Marks; Pedro Miraldo; Kuan-Chuan Peng
Research Areas: Artificial Intelligence, Computer Vision, Machine LearningBrief- MERL researchers are proud to present 7 papers, including two highlight papers (top 3.6% of submissions), and 2 workshops at CVPR 2026. CVPR, taking place from June 3-7 in Denver, CO, USA, is a premier international conference in computer vision.
Papers with MERL Authors:
1. Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting by Xinhang Liu, Pedro Miraldo, Suhas Lohit, Huaizu Jiang, Naoko Sawada, Yu-Wing Tai, Chi-Keung Tang, and Moitreya Chatterjee (Highlight Paper)
2. Parallel Rigidity Matters for Bundle Adjustment by Lalit Manam and Venu Govindu (Highlight Paper)
3. Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling by Valter Piedade, Lalit Manam, Masashi Yamazaki, and Pedro Miraldo
4. AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects by Danrui Li, Jiahao Zhang, Bernhard Egger, Moitreya Chatterjee, Suhas Lohit, Tim K. Marks, and Anoop Cherian
5. LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction by Tianye Ding, Yiming Xie, Yiqing Liang, Moitreya Chatterjee, Pedro Miraldo, and Huaizu Jiang
6. SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification by Jun-Wei Hsieh, Ying-Hsuan Wu, Yi-Kuan Hsieh, Xin Li, Kuan-Chuan Peng, Ming-Ching Chang (CVPR Findings paper)
7. MMHOI: Complex 3D Multi-Human-Object Interaction Understanding by Kaen Kogashi and Anoop Cherian (PhysHuman Workshop paper)
Workshops Co-Organized by MERL:
1. Multimodal Algorithmic Reasoning Workshop by Anoop Cherian, Suhas Lohit, Kuan-Chuan Peng, Honglu Zhou, Kevin Smith, and Josh Tenenbaum
2. The Third Workshop on Anomaly Detection with Foundation Models by Kuan-Chuan Peng, Ying Zhao, and Abhishek Aich
- MERL researchers are proud to present 7 papers, including two highlight papers (top 3.6% of submissions), and 2 workshops at CVPR 2026. CVPR, taking place from June 3-7 in Denver, CO, USA, is a premier international conference in computer vision.
-
TALK [MERL Seminar Series 2026] Zac Manchester presents talk titled Is locomotion really that hard… and other musings on the virtues of simplicity Date & Time: Tuesday, January 20, 2026; 12:00 PM
Speaker: Zac Manchester, MIT
MERL Host: Pedro Miraldo
Research Areas: Computer Vision, Control, Optimization, RoboticsAbstract For decades, legged locomotion was a challenging research topic in robotics. In the last few years, however, both model-based and reinforcement-learning approaches have not only demonstrated impressive performance in laboratory settings, but are now regularly deployed "in the wild." One surprising feature of these successful controllers is how simple they can be. Meanwhile, Art Bryson’s timeless advice to control engineers, “Be wise – linearize,” seems to be increasingly falling out of fashion and at risk of being forgotten by the next generation of practitioners. This talk will discuss several recent works from my group that try to push the limits of how simple locomotion (and, possibly, manipulation) controllers for general-purpose robots can be from several different viewpoints, while also making connections to state-of-the-art generative AI methods like diffusion policies.
For decades, legged locomotion was a challenging research topic in robotics. In the last few years, however, both model-based and reinforcement-learning approaches have not only demonstrated impressive performance in laboratory settings, but are now regularly deployed "in the wild." One surprising feature of these successful controllers is how simple they can be. Meanwhile, Art Bryson’s timeless advice to control engineers, “Be wise – linearize,” seems to be increasingly falling out of fashion and at risk of being forgotten by the next generation of practitioners. This talk will discuss several recent works from my group that try to push the limits of how simple locomotion (and, possibly, manipulation) controllers for general-purpose robots can be from several different viewpoints, while also making connections to state-of-the-art generative AI methods like diffusion policies.
See All News & Events for Pedro -
-
Research Highlights
-
Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting -
SLAM-MER: Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling -
SAC-GNC: SAmple Consensus for adaptive Graduated Non-Convexity -
PS-NeuS: A Probability-guided Sampler for Neural Implicit Surface Rendering -
Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-Aware Spatio-Temporal Sampling
-
-
MERL Publications
- , "Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2026.BibTeX TR2026-077 PDF
- @inproceedings{Liu2026jun,
- author = {Liu, Xinhang and Miraldo, Pedro and Lohit, Suhas and Jiang, Huaizu and Sawada, Naoko and Tai, Yu-Wing and Tang, Chi-Keung and Chatterjee, Moitreya},
- title = {{Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-077}
- }
- , "LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), May 2026.BibTeX TR2026-055 PDF
- @inproceedings{Ding2026may,
- author = {Ding, Tianye and Xie, Yiming and Liang, Yiqing and Chatterjee, Moitreya and Miraldo, Pedro and Jiang, Huaizu},
- title = {{LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2026,
- month = may,
- url = {https://www.merl.com/publications/TR2026-055}
- }
- , "Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), May 2026.BibTeX TR2026-056 PDF Video Software Presentation
- @inproceedings{Piedade2026may,
- author = {{Piedade, Valter and Manam, Lalit and Yamazaki, Masashi and Miraldo, Pedro}},
- title = {{Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2026,
- month = may,
- url = {https://www.merl.com/publications/TR2026-056}
- }
- , "FLIGHT: Fibonacci Lattice-based Inference for Geometric Heading in real-Time", arXiv, February 2026.BibTeX arXiv
- @article{Dirnfeld2026feb,
- author = {Dirnfeld, David and Delattre, Fabien and Miraldo, Pedro and Learned-Miller, Erik},
- title = {{FLIGHT: Fibonacci Lattice-based Inference for Geometric Heading in real-Time}},
- journal = {arXiv},
- year = 2026,
- month = feb,
- url = {https://arxiv.org/abs/2602.23115}
- }
- , "RAPTR: Radar-based 3D Pose Estimation using Transformer", Advances in Neural Information Processing Systems (NeurIPS), December 2025.BibTeX TR2026-006 PDF Software
- @inproceedings{Kato2025dec,
- author = {Kato, Sorachi and Yataka, Ryoma and Wang, Pu and Miraldo, Pedro and Fujihashi, Takuya and Boufounos, Petros T.},
- title = {{RAPTR: Radar-based 3D Pose Estimation using Transformer}},
- booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
- year = 2025,
- month = dec,
- url = {https://www.merl.com/publications/TR2026-006}
- }
- , "Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2026.
-
Other Publications
- , "On Incremental Structure-from-Motion using Lines", IEEE Trans. Robotics (T-RO), Vol. 38, No. 1, pp. 391-406, 2022.BibTeX
- @Article{j32,
- author = {Mateus, Andr\'e and Tahri, Omar and Aguiar, A. Pedro and Lima, Pedro U. and Pedro Miraldo},
- title = {On Incremental Structure-from-Motion using Lines},
- journal = {IEEE Trans. Robotics (T-RO)},
- year = 2022,
- volume = 38,
- number = 1,
- pages = {391--406},
- note = {[\href{https://arxiv.org/abs/2105.11196}{arXiv:2105.11196}, \href{https://doi.org/10.1109/TRO.2021.3085487}{doi}]}
- }
- , "Solving the discrete Euler-Arnold equations for the generalized rigid body motion", Journal of Computational and Applied Mathematics (CAM), Vol. 402, pp. 113814, 2022.BibTeX
- @Article{j33,
- author = {Cardoso, Jo{\~a}o R. and Pedro Miraldo},
- title = {Solving the discrete Euler-Arnold equations for the generalized rigid body motion},
- journal = {Journal of Computational and Applied Mathematics (CAM)},
- year = 2022,
- volume = 402,
- pages = 113814,
- note = {[\href{https://arxiv.org/abs/2109.00505}{\it arXiv:2109.00505}, \href{https://doi.org/10.1016/j.cam.2021.113814}{doi}]}
- }
- , "An observer cascade for velocity and multiple line estimation", IEEE Int'l Conf. Robotics and Automation (ICRA), 2022.BibTeX
- @Inproceedings{j34,
- author = {Mateus, Andr\'e and Lima, Pedro U. and Pedro Miraldo},
- title = {An observer cascade for velocity and multiple line estimation},
- booktitle = {IEEE Int'l Conf. Robotics and Automation (ICRA)},
- year = 2022,
- note = {[\href{https://arxiv.org/abs/2203.01879}{arXiv:2203.01879},{doi}]}
- }
- , "Active Depth Estimation: Stability Analysis and its Applications", IEEE Int'l Conf. Robotics and Automation (ICRA), 2020, pp. 2002-2008.BibTeX
- @Inproceedings{j26,
- author = {Rodrigues, R. T. and P. Miraldo and Dimarogonas, D. V. and Aguiar, A. P.},
- title = {Active Depth Estimation: Stability Analysis and its Applications},
- booktitle = {IEEE Int'l Conf. Robotics and Automation (ICRA)},
- year = 2020,
- pages = {2002--2008},
- note = {[\href{https://arxiv.org/abs/2003.07137}{\it arXiv:2003.07137},\href{https://doi.org/10.1109/ICRA40945.2020.9196670}{doi}]}
- }
- , "3DRegNet: A Deep Neural Network for 3D Point Registration", IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2020, pp. 7191-7201.BibTeX
- @Inproceedings{j27,
- author = {Pais, G. Dias and Ramalingam, Srikumar and Govindu, Venu Madhav and Nascimento, Jacinto C. and Chellappa, Rama and Pedro Miraldo},
- title = {3DRegNet: A Deep Neural Network for 3D Point Registration},
- booktitle = {IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR)},
- year = 2020,
- pages = {7191--7201},
- note = {[\href{https://arxiv.org/abs/1904.01701}{\it arXiv:1904.01701},\href{https://doi.org/10.1109/CVPR42600.2020.00722}{doi}]}
- }
- , "Minimal Solvers for 3D Scan Alignment with Pairs of Intersecting Lines", IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2020, pp. 7232-7242.BibTeX
- @Inproceedings{j28,
- author = {Mateus, Andr{\'e} and Ramalingam, Srikumar and Pedro Miraldo},
- title = {Minimal Solvers for 3D Scan Alignment with Pairs of Intersecting Lines},
- booktitle = {IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR)},
- year = 2020,
- pages = {7232--7242},
- note = {[\href{https://doi.org/10.1109/CVPR42600.2020.00726}{doi}]}
- }
- , "On the Generalized Essential Matrix Correction: An efficient solution to the problem and its applications", Journal of Mathematical Imaging and Vision, Vol. 62, pp. 1107-1120, 2020.BibTeX
- @Article{j29,
- author = {Pedro Miraldo and Cardoso, Jo{\~a}o R.},
- title = {On the Generalized Essential Matrix Correction: An efficient solution to the problem and its applications},
- journal = {Journal of Mathematical Imaging and Vision},
- year = 2020,
- volume = 62,
- pages = {1107--1120},
- note = {[\href{https://arxiv.org/abs/1709.06328}{\it arXiv:1709.06328}, \href{https://doi.org/10.1007/s10851-020-00961-w}{doi}]}
- }
- , "Fast Model Predictive Image-Based Visual Servoing for Quadrotors", IEEE/RSJ Int'l Conf. Intelligent Robots and Systems (IROS), 2020, pp. 7566-7572.BibTeX
- @Inproceedings{j30,
- author = {Roque, Pedro and Bin, Elisa and Pedro Miraldo and Dimarogonas, Dimos V.},
- title = {Fast Model Predictive Image-Based Visual Servoing for Quadrotors},
- booktitle = {IEEE/RSJ Int'l Conf. Intelligent Robots and Systems (IROS)},
- year = 2020,
- pages = {7566--7572},
- note = {[\href{https://doi.org/10.1109/IROS45743.2020.9340759}{doi}]}
- }
- , "Mapping of Sparse 3D Data using Alternating Projection", Asian Conf. Computer Vision (ACCV), 2020, pp. 295-313.BibTeX
- @Inproceedings{j31,
- author = {Ranade, Siddhant and Xin, Yu and Kakkar, Shantnu and Pedro Miraldo and Ramalingam, Srikumar},
- title = {Mapping of Sparse 3D Data using Alternating Projection},
- booktitle = {Asian Conf. Computer Vision (ACCV)},
- year = 2020,
- pages = {295--313},
- note = {[\href{https://arxiv.org/abs/2010.02516}{\it arXiv:2010.02516},\href{https://doi.org/10.1007/978-3-030-69525-5_18}{doi}]}
- }
- , "POSEAMM: A Unified Framework for Solving Pose Problems using an Alternating Minimization Method", IEEE Int'l Conf. Robotics and Automation (ICRA), 2019, pp. 3493-3499.BibTeX
- @Inproceedings{j21,
- author = {Campos, J. and Rodrigues, J. R. and P. Miraldo},
- title = {POSEAMM: A Unified Framework for Solving Pose Problems using an Alternating Minimization Method},
- booktitle = {IEEE Int'l Conf. Robotics and Automation (ICRA)},
- year = 2019,
- pages = {3493--3499},
- note = {[\href{https://arxiv.org/abs/1904.04858}{\it arXiv:1904.04858}, \href{https://doi.org/10.1109/ICRA.2019.8793694}{doi}]}
- }
- , "OmniDRL: Robust Pedestrian Detection using Deep Reinforcement Learning on Omnidirectional Cameras", IEEE Int'l Conf. Robotics and Automation (ICRA), 2019, pp. 4782-4789.BibTeX
- @Inproceedings{j22,
- author = {Pais, G. and Nascimento, J. C. and P. Miraldo},
- title = {OmniDRL: Robust Pedestrian Detection using Deep Reinforcement Learning on Omnidirectional Cameras},
- booktitle = {IEEE Int'l Conf. Robotics and Automation (ICRA)},
- year = 2019,
- pages = {4782--4789},
- note = {[\href{https://arxiv.org/abs/1903.00676}{\it arXiv:1903.00676}, \href{https://doi.org/10.1109/ICRA.2019.8794471}{doi}]}
- }
- , "Minimal Solvers for Mini-Loop Closures in 3D Multi-Scan Alignment", IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2019, pp. 9691-9700.BibTeX
- @Inproceedings{j23,
- author = {P. Miraldo and Saha, S. and Ramalingam, S.},
- title = {Minimal Solvers for Mini-Loop Closures in 3D Multi-Scan Alignment},
- booktitle = {IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR)},
- year = 2019,
- pages = {9691--9700},
- note = {[\href{https://arxiv.org/abs/1904.03941}{\it arXiv:1904.03941}, \href{https://doi.org/10.1109/CVPR.2019.00993}{doi}]}
- }
- , "A Framework for Depth Estimation and Relative Localization of Ground Robots using Computer Vision", IEEE/RSJ Int'l Conf. Intelligent Robots and Systems (IROS), 2019, pp. 3719-3724.BibTeX
- @Inproceedings{j24,
- author = {Rodrigues, R. and P. Miraldo and Dimarogonas, D. V. and Aguiar, A. P.},
- title = {A Framework for Depth Estimation and Relative Localization of Ground Robots using Computer Vision},
- booktitle = {IEEE/RSJ Int'l Conf. Intelligent Robots and Systems (IROS)},
- year = 2019,
- pages = {3719--3724},
- note = {[\href{https://arxiv.org/abs/1908.00309}{\it arXiv:1908.00309}, \href{https://doi.org/10.1109/IROS40897.2019.8968459}{doi}]}
- }
- , "SocRob$@$Home Integrating AI Components in a Domestic Robot System", Künstliche Intelligenz (KI), Vol. 33, No. 4, pp. 343-356, 2019.BibTeX
- @Article{j25,
- author = {Lima, P. U. and Azevedo, C. and Brzozowska, E. and Cartucho, J. and Dias, T. J. and Gon\c{c}alves, J. and Kinarullathil, M. and Lawless, G. and Lima, O. and Luz, R. and P. Miraldo and Piazza, E. and Silva, M. and Veiga, T. and Ventura, R.},
- title = {SocRob$@$Home Integrating AI Components in a Domestic Robot System},
- journal = {K\"{u}nstliche Intelligenz (KI)},
- year = 2019,
- volume = 33,
- number = 4,
- pages = {343--356},
- note = {[\href{https://doi.org/10.1007/s13218-019-00618-w}{doi}]}
- }
- , "Generic distortion model for metrology under optical microscopes", Optics and Lasers in Engineering (OLEN), Vol. 103, pp. 119-126, 2018.BibTeX
- @Article{j15,
- author = {Liu, X. and Li, Z. and Zhong, K. and Chao, Y. and P. Miraldo and Shi, Y.},
- title = {Generic distortion model for metrology under optical microscopes},
- journal = {Optics and Lasers in Engineering (OLEN)},
- year = 2018,
- volume = 103,
- pages = {119--126},
- note = {[\href{https://doi.org/10.1016/j.optlaseng.2017.12.006}{doi}]}
- }
- , "Low-level Active Visual Navigation: Increasing robustness of vision-based localization using potential fields", IEEE Robotics and Automation Letters (RA-L) and IEEE Int'l Conf. Robotics and Automation (ICRA), Vol. 3, No. 3, pp. 2079-2086, 2018.BibTeX
- @Article{j16,
- author = {Rodrigues, R. and Basiri, M. and Aguiar, A. P. and P. Miraldo},
- title = {Low-level Active Visual Navigation: Increasing robustness of vision-based localization using potential fields},
- journal = {IEEE Robotics and Automation Letters (RA-L) and IEEE Int'l Conf. Robotics and Automation (ICRA)},
- year = 2018,
- volume = 3,
- number = 3,
- pages = {2079--2086},
- note = {[\href{https://arxiv.org/abs/1801.07249}{\it arXiv:1801.07249}, \href{https://doi.org/10.1109/LRA.2018.2809628}{doi}]}
- }
- , "Analytical Modeling of Vanishing Points and Curves in Catadioptric Cameras", IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2018, pp. 2012-2021.BibTeX
- @Inproceedings{j17,
- author = {P. Miraldo and Eiras, F. and Ramalingam, S.},
- title = {Analytical Modeling of Vanishing Points and Curves in Catadioptric Cameras},
- booktitle = {IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR)},
- year = 2018,
- pages = {2012--2021},
- note = {[\href{https://arxiv.org/abs/1804.09460}{\it arXiv:1804.09460}, \href{https://doi.org/10.1109/CVPR.2018.00215}{doi}]}
- }
- , "Active Structure-from-Motion for 3D Straight Lines", IEEE/RSJ Int'l Conf. Intelligent Robots and Systems (IROS), 2018, pp. 5819-5825.BibTeX
- @Inproceedings{j18,
- author = {Mateus, A. and Tahri, O. and P. Miraldo},
- title = {Active Structure-from-Motion for 3D Straight Lines},
- booktitle = {IEEE/RSJ Int'l Conf. Intelligent Robots and Systems (IROS)},
- year = 2018,
- pages = {5819--5825},
- note = {[\href{https://arxiv.org/abs/1807.00753}{\it arXiv:1807.00753}, \href{https://doi.org/10.1109/IROS.2018.8593793}{doi}]}
- }
- , "A Minimal Closed-Form Solution for Multi-Perspective Pose Estimation using Points and Lines", European Conf. Computer Vision (ECCV), 2018, pp. 490-507.BibTeX
- @Inproceedings{j19,
- author = {P. Miraldo and Dias, T. and Ramalingam, S.},
- title = {A Minimal Closed-Form Solution for Multi-Perspective Pose Estimation using Points and Lines},
- booktitle = {European Conf. Computer Vision (ECCV)},
- year = 2018,
- pages = {490--507},
- note = {[\href{https://arxiv.org/abs/1807.09970}{\it arXiv:1807.09970}, \href{https://doi.org/10.1007/978-3-030-01270-0_29}{doi}]}
- }
- , "Efficient and Robust Pedestrian Detection using Deep Learning for Human-Aware Navigation", Robotics and Autonomous Systems (RAS), Vol. 113, pp. 23-37, 2018.BibTeX
- @Article{j20,
- author = {Mateus, A. and Ribeiro, D. and P. Miraldo and Nascimento, J. C.},
- title = {Efficient and Robust Pedestrian Detection using Deep Learning for Human-Aware Navigation},
- journal = {Robotics and Autonomous Systems (RAS)},
- year = 2018,
- volume = 113,
- pages = {23--37},
- note = {[\href{https://arxiv.org/abs/1607.04441}{\it arXiv:1607.04441}, \href{https://doi.org/10.1016/j.robot.2018.12.007}{doi}]}
- }
- , "A framework to calibrate the scanning electron microscope under any magnifications", IEEE Photonics Technology Letters (PT-L), Vol. 28, No. 16, pp. 1715-1718, 2016.BibTeX
- @Article{j12,
- author = {Liu, X. and Li, Z. and P. Miraldo and Zhong, K. and Shi, Y.},
- title = {A framework to calibrate the scanning electron microscope under any magnifications},
- journal = {IEEE Photonics Technology Letters (PT-L)},
- year = 2016,
- volume = 28,
- number = 16,
- pages = {1715--1718},
- note = {[\href{https://doi.org/10.1109/LPT.2016.2522758}{doi}]}
- }
- , "Efficient Object Search for Mobile Robots in Dynamic Environments: Semantic Map as an Input for the Decision Maker", IEEE/RSJ Int'l Conf. Intelligent Robots and Systems (IROS), 2016, pp. 2745-2750.BibTeX
- @Inproceedings{j13,
- author = {Veiga, T. and P. Miraldo and Ventura, R. and Lima, P.},
- title = {Efficient Object Search for Mobile Robots in Dynamic Environments: Semantic Map as an Input for the Decision Maker},
- booktitle = {IEEE/RSJ Int'l Conf. Intelligent Robots and Systems (IROS)},
- year = 2016,
- pages = {2745--2750},
- note = {[\href{https://doi.org/10.1109/IROS.2016.7759426}{doi}]}
- }
- , "Competitions for Benchmarking: Task and Functionality Scoring Complete Performance Assessment", IEEE Robotics Automation Magazine (RA-M), Vol. 22, No. 3, pp. 53-61, 2015.BibTeX
- @Article{j10,
- author = {Amigoni, F. and Berghofer, J. and Bonarini, A. and G. Fontana, N. Hochgeschwender and Iocchi, L. and Kraetzschmar, G. K. and Lima, P. and Matteucci, M. and P. Miraldo and Nardi, D. and Schiaonati, V.},
- title = {Competitions for Benchmarking: Task and Functionality Scoring Complete Performance Assessment},
- journal = {IEEE Robotics Automation Magazine (RA-M)},
- year = 2015,
- volume = 22,
- number = 3,
- pages = {53--61},
- note = {[\href{https://doi.org/10.1109/MRA.2015.2448871}{doi}]}
- }
- , "Direct Solution to the Minimal Generalized Pose", IEEE Trans. Cybernetics (T-CYB), Vol. 45, No. 3, pp. 404-415, 2015.BibTeX
- @Article{j5,
- author = {P. Miraldo and Araujo, H.},
- title = {Direct Solution to the Minimal Generalized Pose},
- journal = {IEEE Trans. Cybernetics (T-CYB)},
- year = 2015,
- volume = 45,
- number = 3,
- pages = {404--415},
- note = {[\href{https://doi.org/10.1109/TCYB.2014.2326970}{doi}]}
- }
- , "Pose Estimation for General Cameras Using Lines", IEEE Trans. Cybernetics (T-CYB), Vol. 45, No. 10, pp. 2156-2164, 2015.BibTeX
- @Article{j6,
- author = {P. Miraldo and Araujo, H. and Gon\c{c}alves, N.},
- title = {Pose Estimation for General Cameras Using Lines},
- journal = {IEEE Trans. Cybernetics (T-CYB)},
- year = 2015,
- volume = 45,
- number = 10,
- pages = {2156--2164},
- note = {[\href{https://doi.org/10.1109/TCYB.2014.2366378}{doi}]}
- }
- , "Generalized Essential Matrix: Properties of the Singular Value Decomposition", Image and Vision Computing (IVC), Vol. 34, pp. 45-50, 2015.BibTeX
- @Article{j7,
- author = {P. Miraldo and Araujo, H.},
- title = {Generalized Essential Matrix: Properties of the Singular Value Decomposition},
- journal = {Image and Vision Computing (IVC)},
- year = 2015,
- volume = 34,
- pages = {45--50},
- note = {[\href{https://doi.org/10.1016/j.imavis.2014.11.003}{doi}]}
- }
- , "Pose Estimation for Non-Central Cameras Using Planes", Springer J. Intelligent & Robotic Systems (JINT), Vol. 80, No. 3, pp. 595-608, 2015.BibTeX
- @Article{j8,
- author = {P. Miraldo and Araujo, H.},
- title = {Pose Estimation for Non-Central Cameras Using Planes},
- journal = {Springer J. Intelligent \& Robotic Systems (JINT)},
- year = 2015,
- volume = 80,
- number = 3,
- pages = {595--608},
- note = {[\href{https://doi.org/10.1007/s10846-015-0193-3}{doi}]}
- }
- , "A Simple and Robust Solution to the Minimal General Pose Estimation", IEEE Int'l Conf. Robotics and Automation (ICRA), 2014, pp. 2119-2125.BibTeX
- @Inproceedings{j3,
- author = {P. Miraldo and Araujo, H.},
- title = {A Simple and Robust Solution to the Minimal General Pose Estimation},
- booktitle = {IEEE Int'l Conf. Robotics and Automation (ICRA)},
- year = 2014,
- pages = {2119--2125},
- note = {[\href{https://doi.org/10.1109/ICRA.2014.6907150}{doi}]}
- }
- , "Planar Pose Estimation for General Cameras using Known 3D Lines", IEEE/RSJ Int'l Conf. Intelligent Robots and Systems (IROS), 2014, pp. 4234-4240.BibTeX
- @Inproceedings{j4,
- author = {P. Miraldo and Araujo, H.},
- title = {Planar Pose Estimation for General Cameras using Known 3D Lines},
- booktitle = {IEEE/RSJ Int'l Conf. Intelligent Robots and Systems (IROS)},
- year = 2014,
- pages = {4234--4240},
- note = {[\href{https://doi.org/10.1109/IROS.2014.6943159}{doi}]}
- }
- , "Calibration of Smooth Camera Models", IEEE Trans. Pattern Analysis and Machine Intelligence (T-PAMI), Vol. 35, No. 9, pp. 2091-2103, 2013.BibTeX
- @Article{j2,
- author = {P. Miraldo and Araujo, H.},
- title = {Calibration of Smooth Camera Models},
- journal = {IEEE Trans. Pattern Analysis and Machine Intelligence (T-PAMI)},
- year = 2013,
- volume = 35,
- number = 9,
- pages = {2091--2103},
- note = {[\href{https://doi.org/10.1109/TPAMI.2012.258}{doi}]}
- }
- , "Point-based Calibration Using a Parametric Representation of General Imaging Models", IEEE/CVF Int'l Conf. Computer Vision (ICCV), 2011, pp. 2304-2311.BibTeX
- @Inproceedings{j1,
- author = {P. Miraldo and Araujo, H. and Queir\'{o}, J.},
- title = {Point-based Calibration Using a Parametric Representation of General Imaging Models},
- booktitle = {IEEE/CVF Int'l Conf. Computer Vision (ICCV)},
- year = 2011,
- pages = {2304--2311},
- note = {[\href{https://doi.org/10.1109/ICCV.2011.6126511}{doi}]}
- }
- , "On Incremental Structure-from-Motion using Lines", IEEE Trans. Robotics (T-RO), Vol. 38, No. 1, pp. 391-406, 2022.
-
Software & Data Downloads
-
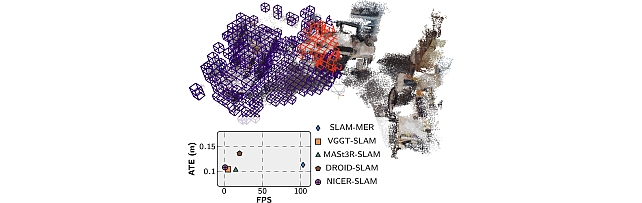
Mitsubishi Electric Research framework for visual SLAM -
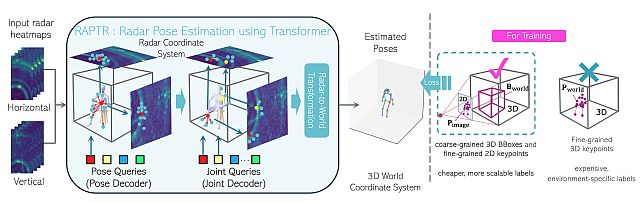
Radar-based 3D Pose Estimation using Transformer -
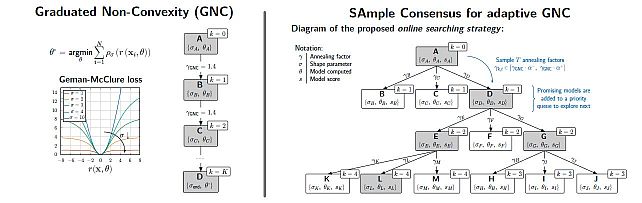
SAmple Consensus for Adaptive Graduated Non-Convexity -
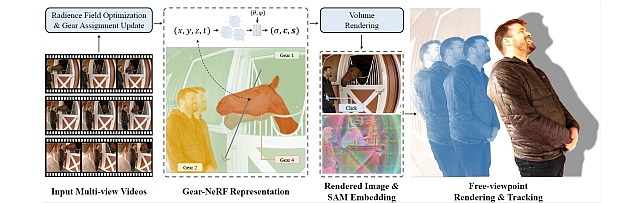
Gear Extensions of Neural Radiance Fields -

BAyesian Network for adaptive SAmple Consensus -
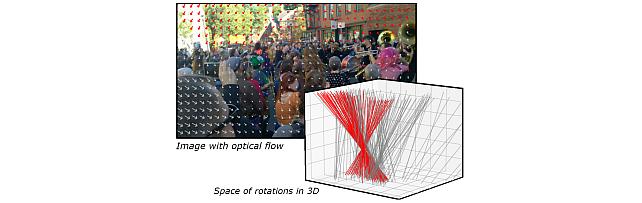
Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes
-
-
Videos
-
MERL Issued Patents
-
Title: "ORIENTED-GRID ENCODER FOR 3D IMPLICIT REPRESENTATION"
Inventors: Miraldo, Pedro; Pais, Goncalo; Gaur, Arihant
Patent No.: 12,633,058
Issue Date: May 19, 2026 -
Title: "NEURAL RADIANCE FIELD TRAINING BASED ON A NON-UNIFORM SAMPLE OF IMAGE PIXELS"
Inventors: Miraldo, Pedro; Greiff, Marcus; Pais, Goncalo; Chatterjee, Moitreya
Patent No.: 12,633,035
Issue Date: May 19, 2026 -
Title: "Rendering Two-Dimensional Image of a Dynamic Three-Dimensional Scene"
Inventors: Chatterjee, Moitreya; Lohit, Suhas; Miraldo, Pedro
Patent No.: 12,475,636
Issue Date: Nov 18, 2025
-
Title: "ORIENTED-GRID ENCODER FOR 3D IMPLICIT REPRESENTATION"