Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-Aware Spatio-Temporal Sampling
Motion-aware novel view rendering and tracking.
MERL Researchers: Moitreya Chatterjee, Pedro Miraldo, Suhas Lohit.
Joint work with: Xinhang Liu (The Hong Kong University of Science and Technology), Yu-Wing Tai (Dartmouth College), Chi-Keung Tang (The Hong Kong University of Science and Technology)
Search MERL publications by keyword: Computer Vision , Machine Learning , Artificial Intelligence
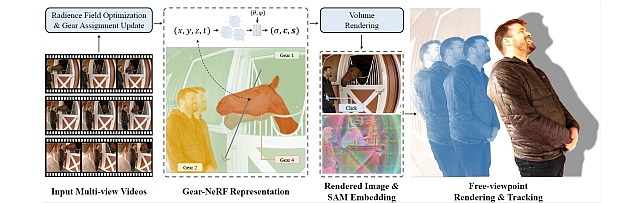
Free-viewpoint rendering aims to realize a realistic rendering of a 3D scene that is consistent with the geometry of the 3D scene, when rendered from any given viewing direction. To make such systems ubiquitous, it is essential that they be capable of handling dynamic scenes, i.e. those where objects change in their position or configuration or both over time. Existing approaches for this task, propose pipelines that are agnostic to the semantic content of the scene and thus treat every region in the 3D space, as being equally important, when rendering. This results in the system struggling to render the regions of the scene that have high motion. In this paper, we depart from such a simplistic training pipeline by adjusting the spatio-temporal sampling resolution of the different semantic regions of the scene, based on the extent of their motion. These regions are grouped based on this criterion and each such region is called a Gear. We propose to sample more densely from regions with high motion, i.e. those that are assigned higher gears, during training. This results in noticeable improvement in rendering quality over the state-of-the-art approaches, across a wide variety of dynamic scenes. Furthermore, almost for free, our proposed method enables free-viewpoint tracking of objects of interest starting from a single mouse click - a functionality not yet achieved by prior methods.


Details of the model
Our method works by learning a 4D (spatio-temporal) feature volume which captures the photometric characteristics of the scene. One such feature volume is learned for each of the gear-levels. Additionally, in order to derive semantic knowledge of the scene, we also learn 4D feature volume of Segment Anything Model (SAM) representations which segments the rendered scene into semantic components. In order to assign the different regions of the scene to appropriate gear-levels, we adopt an iterative approach. In every step, we increase the gear-level assigned to the region (as determined by SAM) with the most lossy rendering, as shown in the figure to the left (above). For such regions, we sample, more densely spatio-temporally, as shown in the figure to the right (above).
Software & Data Downloads
MERL News & Events
-
NEWS MERL Papers and Workshops at CVPR 2024 Date: June 17, 2024 - June 21, 2024
Where: Seattle, WA
MERL Contacts: Petros T. Boufounos; Moitreya Chatterjee; Anoop Cherian; Michael J. Jones; Toshiaki Koike-Akino; Jonathan Le Roux; Suhas Lohit; Tim K. Marks; Pedro Miraldo; Jing Liu; Kuan-Chuan Peng; Pu (Perry) Wang; Ye Wang; Matthew Brand
Research Areas: Artificial Intelligence, Computational Sensing, Computer Vision, Machine Learning, Speech & AudioBrief- MERL researchers are presenting 5 conference papers, 3 workshop papers, and are co-organizing two workshops at the CVPR 2024 conference, which will be held in Seattle, June 17-21. CVPR is one of the most prestigious and competitive international conferences in computer vision. Details of MERL contributions are provided below.
CVPR Conference Papers:
1. "TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models" by H. Ni, B. Egger, S. Lohit, A. Cherian, Y. Wang, T. Koike-Akino, S. X. Huang, and T. K. Marks
This work enables a pretrained text-to-video (T2V) diffusion model to be additionally conditioned on an input image (first video frame), yielding a text+image to video (TI2V) model. Other than using the pretrained T2V model, our method requires no ("zero") training or fine-tuning. The paper uses a "repeat-and-slide" method and diffusion resampling to synthesize videos from a given starting image and text describing the video content.
Paper: https://www.merl.com/publications/TR2024-059
Project page: https://merl.com/research/highlights/TI2V-Zero
2. "Long-Tailed Anomaly Detection with Learnable Class Names" by C.-H. Ho, K.-C. Peng, and N. Vasconcelos
This work aims to identify defects across various classes without relying on hard-coded class names. We introduce the concept of long-tailed anomaly detection, addressing challenges like class imbalance and dataset variability. Our proposed method combines reconstruction and semantic modules, learning pseudo-class names and utilizing a variational autoencoder for feature synthesis to improve performance in long-tailed datasets, outperforming existing methods in experiments.
Paper: https://www.merl.com/publications/TR2024-040
3. "Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-aware Spatio-Temporal Sampling" by X. Liu, Y-W. Tai, C-T. Tang, P. Miraldo, S. Lohit, and M. Chatterjee
This work presents a new strategy for rendering dynamic scenes from novel viewpoints. Our approach is based on stratifying the scene into regions based on the extent of motion of the region, which is automatically determined. Regions with higher motion are permitted a denser spatio-temporal sampling strategy for more faithful rendering of the scene. Additionally, to the best of our knowledge, ours is the first work to enable tracking of objects in the scene from novel views - based on the preferences of a user, provided by a click.
Paper: https://www.merl.com/publications/TR2024-042
4. "SIRA: Scalable Inter-frame Relation and Association for Radar Perception" by R. Yataka, P. Wang, P. T. Boufounos, and R. Takahashi
Overcoming the limitations on radar feature extraction such as low spatial resolution, multipath reflection, and motion blurs, this paper proposes SIRA (Scalable Inter-frame Relation and Association) for scalable radar perception with two designs: 1) extended temporal relation, generalizing the existing temporal relation layer from two frames to multiple inter-frames with temporally regrouped window attention for scalability; and 2) motion consistency track with a pseudo-tracklet generated from observational data for better object association.
Paper: https://www.merl.com/publications/TR2024-041
5. "RILA: Reflective and Imaginative Language Agent for Zero-Shot Semantic Audio-Visual Navigation" by Z. Yang, J. Liu, P. Chen, A. Cherian, T. K. Marks, J. L. Roux, and C. Gan
We leverage Large Language Models (LLM) for zero-shot semantic audio visual navigation. Specifically, by employing multi-modal models to process sensory data, we instruct an LLM-based planner to actively explore the environment by adaptively evaluating and dismissing inaccurate perceptual descriptions.
Paper: https://www.merl.com/publications/TR2024-043
CVPR Workshop Papers:
1. "CoLa-SDF: Controllable Latent StyleSDF for Disentangled 3D Face Generation" by R. Dey, B. Egger, V. Boddeti, Y. Wang, and T. K. Marks
This paper proposes a new method for generating 3D faces and rendering them to images by combining the controllability of nonlinear 3DMMs with the high fidelity of implicit 3D GANs. Inspired by StyleSDF, our model uses a similar architecture but enforces the latent space to match the interpretable and physical parameters of the nonlinear 3D morphable model MOST-GAN.
Paper: https://www.merl.com/publications/TR2024-045
2. “Tracklet-based Explainable Video Anomaly Localization” by A. Singh, M. J. Jones, and E. Learned-Miller
This paper describes a new method for localizing anomalous activity in video of a scene given sample videos of normal activity from the same scene. The method is based on detecting and tracking objects in the scene and estimating high-level attributes of the objects such as their location, size, short-term trajectory and object class. These high-level attributes can then be used to detect unusual activity as well as to provide a human-understandable explanation for what is unusual about the activity.
Paper: https://www.merl.com/publications/TR2024-057
MERL co-organized workshops:
1. "Multimodal Algorithmic Reasoning Workshop" by A. Cherian, K-C. Peng, S. Lohit, M. Chatterjee, H. Zhou, K. Smith, T. K. Marks, J. Mathissen, and J. Tenenbaum
Workshop link: https://marworkshop.github.io/cvpr24/index.html
2. "The 5th Workshop on Fair, Data-Efficient, and Trusted Computer Vision" by K-C. Peng, et al.
Workshop link: https://fadetrcv.github.io/2024/
3. "SuperLoRA: Parameter-Efficient Unified Adaptation for Large Vision Models" by X. Chen, J. Liu, Y. Wang, P. Wang, M. Brand, G. Wang, and T. Koike-Akino
This paper proposes a generalized framework called SuperLoRA that unifies and extends different variants of low-rank adaptation (LoRA). Introducing new options with grouping, folding, shuffling, projection, and tensor decomposition, SuperLoRA offers high flexibility and demonstrates superior performance up to 10-fold gain in parameter efficiency for transfer learning tasks.
Paper: https://www.merl.com/publications/TR2024-062
- MERL researchers are presenting 5 conference papers, 3 workshop papers, and are co-organizing two workshops at the CVPR 2024 conference, which will be held in Seattle, June 17-21. CVPR is one of the most prestigious and competitive international conferences in computer vision. Details of MERL contributions are provided below.
MERL Publications
- , "Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-aware Spatio-Temporal Sampling", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), May 2024, pp. 19667-19679.BibTeX TR2024-042 PDF Videos Software
- @inproceedings{Liu2024may,
- author = {Liu, Xinhang and Tai, Yu-wing and Tang, Chi-Keung and Miraldo, Pedro and Lohit, Suhas and Chatterjee, Moitreya},
- title = {{Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-aware Spatio-Temporal Sampling}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2024,
- pages = {19667--19679},
- month = may,
- publisher = {IEEE},
- url = {https://www.merl.com/publications/TR2024-042}
- }