Moitreya Chatterjee

- Phone: 617-621-7592
- Email:
-
Position:
Research / Technical Staff
Research Scientist -
Education:
Ph.D., University of Illinois at Urbana-Champaign, 2022 -
Research Areas:
Moitreya's Quick Links
-
Biography
Moitreya's research interests are in computer vision, and multimodal machine learning with a particular emphasis on learning from audio-visual data. His PhD work received the Joan and Lalit Bahl Fellowship and the Thomas and Margaret Huang Research Award. Earlier, he earned a M.S. degree in Computer Science from the University of Southern California (USC), during which he received an Outstanding Paper Award from the ACM International Conference on Multimodal Interaction (ICMI).
-
Recent News & Events
-
NEWS MERL Presents 7 Papers and 2 Workshops at CVPR 2026 Date: June 3, 2026 - June 7, 2026
Where: Colorado Convention Center, Denver, Colorado
MERL Contacts: Moitreya Chatterjee; Anoop Cherian; Kaen Kogashi; Suhas Lohit; Lalit Manam; Tim K. Marks; Pedro Miraldo; Kuan-Chuan Peng
Research Areas: Artificial Intelligence, Computer Vision, Machine LearningBrief- MERL researchers are proud to present 7 papers, including two highlight papers (top 3.6% of submissions), and 2 workshops at CVPR 2026. CVPR, taking place from June 3-7 in Denver, CO, USA, is a premier international conference in computer vision.
Papers with MERL Authors:
1. Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting by Xinhang Liu, Pedro Miraldo, Suhas Lohit, Huaizu Jiang, Naoko Sawada, Yu-Wing Tai, Chi-Keung Tang, and Moitreya Chatterjee (Highlight Paper)
2. Parallel Rigidity Matters for Bundle Adjustment by Lalit Manam and Venu Govindu (Highlight Paper)
3. Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling by Valter Piedade, Lalit Manam, Masashi Yamazaki, and Pedro Miraldo
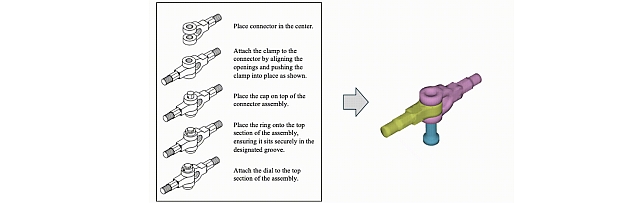
4. AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects by Danrui Li, Jiahao Zhang, Bernhard Egger, Moitreya Chatterjee, Suhas Lohit, Tim K. Marks, and Anoop Cherian
5. LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction by Tianye Ding, Yiming Xie, Yiqing Liang, Moitreya Chatterjee, Pedro Miraldo, and Huaizu Jiang
6. SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification by Jun-Wei Hsieh, Ying-Hsuan Wu, Yi-Kuan Hsieh, Xin Li, Kuan-Chuan Peng, Ming-Ching Chang (CVPR Findings paper)
7. MMHOI: Complex 3D Multi-Human-Object Interaction Understanding by Kaen Kogashi and Anoop Cherian (PhysHuman Workshop paper)
Workshops Co-Organized by MERL:
1. Multimodal Algorithmic Reasoning Workshop by Anoop Cherian, Suhas Lohit, Kuan-Chuan Peng, Honglu Zhou, Kevin Smith, and Josh Tenenbaum
2. The Third Workshop on Anomaly Detection with Foundation Models by Kuan-Chuan Peng, Ying Zhao, and Abhishek Aich
- MERL researchers are proud to present 7 papers, including two highlight papers (top 3.6% of submissions), and 2 workshops at CVPR 2026. CVPR, taking place from June 3-7 in Denver, CO, USA, is a premier international conference in computer vision.
-
NEWS MERL Papers and Workshops at CVPR 2025 Date: June 11, 2025 - June 15, 2025
Where: Nashville, TN, USA
MERL Contacts: Matthew Brand; Moitreya Chatterjee; Anoop Cherian; Michael J. Jones; Toshiaki Koike-Akino; Jing Liu; Suhas Lohit; Tim K. Marks; Pedro Miraldo; Kuan-Chuan Peng; Pu (Perry) Wang; Ye Wang
Research Areas: Artificial Intelligence, Computer Vision, Machine Learning, Signal Processing, Speech & AudioBrief- MERL researchers are presenting 2 conference papers, co-organizing two workshops, and presenting 7 workshop papers at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2025 conference, which will be held in Nashville, TN, USA from June 11-15, 2025. CVPR is one of the most prestigious and competitive international conferences in the area of computer vision. Details of MERL contributions are provided below:
Main Conference Papers:
1. "UWAV: Uncertainty-weighted Weakly-supervised Audio-Visual Video Parsing" by Y.H. Lai, J. Ebbers, Y. F. Wang, F. Germain, M. J. Jones, M. Chatterjee
This work deals with the task of weakly‑supervised Audio-Visual Video Parsing (AVVP) and proposes a novel, uncertainty-aware algorithm called UWAV towards that end. UWAV works by producing more reliable segment‑level pseudo‑labels while explicitly weighting each label by its prediction uncertainty. This uncertainty‑aware training, combined with a feature‑mixup regularization scheme, promotes inter‑segment consistency in the pseudo-labels. As a result, UWAV achieves state‑of‑the‑art performance on two AVVP datasets across multiple metrics, demonstrating both effectiveness and strong generalizability.
Paper: https://www.merl.com/publications/TR2025-072
2. "TailedCore: Few-Shot Sampling for Unsupervised Long-Tail Noisy Anomaly Detection" by Y. G. Jung, J. Park, J. Yoon, K.-C. Peng, W. Kim, A. B. J. Teoh, and O. Camps.
This work tackles unsupervised anomaly detection in complex scenarios where normal data is noisy and has an unknown, imbalanced class distribution. Existing models face a trade-off between robustness to noise and performance on rare (tail) classes. To address this, the authors propose TailSampler, which estimates class sizes from embedding similarities to isolate tail samples. Using TailSampler, they develop TailedCore, a memory-based model that effectively captures tail class features while remaining noise-robust, outperforming state-of-the-art methods in extensive evaluations.
paper: https://www.merl.com/publications/TR2025-077
MERL Co-Organized Workshops:
1. Multimodal Algorithmic Reasoning (MAR) Workshop, organized by A. Cherian, K.-C. Peng, S. Lohit, H. Zhou, K. Smith, L. Xue, T. K. Marks, and J. Tenenbaum.
Workshop link: https://marworkshop.github.io/cvpr25/
2. The 6th Workshop on Fair, Data-Efficient, and Trusted Computer Vision, organized by N. Ratha, S. Karanam, Z. Wu, M. Vatsa, R. Singh, K.-C. Peng, M. Merler, and K. Varshney.
Workshop link: https://fadetrcv.github.io/2025/
Workshop Papers:
1. "FreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations" by N. Sawada, P. Miraldo, S. Lohit, T.K. Marks, and M. Chatterjee (Oral)
With their ability to model object surfaces in a scene as a continuous function, neural implicit surface reconstruction methods have made remarkable strides recently, especially over classical 3D surface reconstruction methods, such as those that use voxels or point clouds. Towards this end, we propose FreBIS - a neural implicit‑surface framework that avoids overloading a single encoder with every surface detail. It divides a scene into several frequency bands and assigns a dedicated encoder (or group of encoders) to each band, then enforces complementary feature learning through a redundancy‑aware weighting module. Swapping this frequency‑stratified stack into an off‑the‑shelf reconstruction pipeline markedly boosts 3D surface accuracy and view‑consistent rendering on the challenging BlendedMVS dataset.
paper: https://www.merl.com/publications/TR2025-074
2. "Multimodal 3D Object Detection on Unseen Domains" by D. Hegde, S. Lohit, K.-C. Peng, M. J. Jones, and V. M. Patel.
LiDAR-based object detection models often suffer performance drops when deployed in unseen environments due to biases in data properties like point density and object size. Unlike domain adaptation methods that rely on access to target data, this work tackles the more realistic setting of domain generalization without test-time samples. We propose CLIX3D, a multimodal framework that uses both LiDAR and image data along with supervised contrastive learning to align same-class features across domains and improve robustness. CLIX3D achieves state-of-the-art performance across various domain shifts in 3D object detection.
paper: https://www.merl.com/publications/TR2025-078
3. "Improving Open-World Object Localization by Discovering Background" by A. Singh, M. J. Jones, K.-C. Peng, M. Chatterjee, A. Cherian, and E. Learned-Miller.
This work tackles open-world object localization, aiming to detect both seen and unseen object classes using limited labeled training data. While prior methods focus on object characterization, this approach introduces background information to improve objectness learning. The proposed framework identifies low-information, non-discriminative image regions as background and trains the model to avoid generating object proposals there. Experiments on standard benchmarks show that this method significantly outperforms previous state-of-the-art approaches.
paper: https://www.merl.com/publications/TR2025-058
4. "PF3Det: A Prompted Foundation Feature Assisted Visual LiDAR 3D Detector" by K. Li, T. Zhang, K.-C. Peng, and G. Wang.
This work addresses challenges in 3D object detection for autonomous driving by improving the fusion of LiDAR and camera data, which is often hindered by domain gaps and limited labeled data. Leveraging advances in foundation models and prompt engineering, the authors propose PF3Det, a multi-modal detector that uses foundation model encoders and soft prompts to enhance feature fusion. PF3Det achieves strong performance even with limited training data. It sets new state-of-the-art results on the nuScenes dataset, improving NDS by 1.19% and mAP by 2.42%.
paper: https://www.merl.com/publications/TR2025-076
5. "Noise Consistency Regularization for Improved Subject-Driven Image Synthesis" by Y. Ni., S. Wen, P. Konius, A. Cherian
Fine-tuning Stable Diffusion enables subject-driven image synthesis by adapting the model to generate images containing specific subjects. However, existing fine-tuning methods suffer from two key issues: underfitting, where the model fails to reliably capture subject identity, and overfitting, where it memorizes the subject image and reduces background diversity. To address these challenges, two auxiliary consistency losses are porposed for diffusion fine-tuning. First, a prior consistency regularization loss ensures that the predicted diffusion noise for prior (non- subject) images remains consistent with that of the pretrained model, improving fidelity. Second, a subject consistency regularization loss enhances the fine-tuned model’s robustness to multiplicative noise modulated latent code, helping to preserve subject identity while improving diversity. Our experimental results demonstrate the effectiveness of our approach in terms of image diversity, outperforming DreamBooth in terms of CLIP scores, background variation, and overall visual quality.
paper: https://www.merl.com/publications/TR2025-073
6. "LatentLLM: Attention-Aware Joint Tensor Compression" by T. Koike-Akino, X. Chen, J. Liu, Y. Wang, P. Wang, M. Brand
We propose a new framework to convert a large foundation model such as large language models (LLMs)/large multi- modal models (LMMs) into a reduced-dimension latent structure. Our method uses a global attention-aware joint tensor decomposition to significantly improve the model efficiency. We show the benefit on several benchmark including multi-modal reasoning tasks.
paper: https://www.merl.com/publications/TR2025-075
7. "TuneComp: Joint Fine-Tuning and Compression for Large Foundation Models" by T. Koike-Akino, X. Chen, J. Liu, Y. Wang, P. Wang, M. Brand
To reduce model size during post-training, compression methods, including knowledge distillation, low-rank approximation, and pruning, are often applied after fine- tuning the model. However, sequential fine-tuning and compression sacrifices performance, while creating a larger than necessary model as an intermediate step. In this work, we aim to reduce this gap, by directly constructing a smaller model while guided by the downstream task. We propose to jointly fine-tune and compress the model by gradually distilling it to a pruned low-rank structure. Experiments demonstrate that joint fine-tuning and compression significantly outperforms other sequential compression methods.
paper: https://www.merl.com/publications/TR2025-079
- MERL researchers are presenting 2 conference papers, co-organizing two workshops, and presenting 7 workshop papers at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2025 conference, which will be held in Nashville, TN, USA from June 11-15, 2025. CVPR is one of the most prestigious and competitive international conferences in the area of computer vision. Details of MERL contributions are provided below:
See All News & Events for Moitreya -
-
Research Highlights
-
Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting -
AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects -
PS-NeuS: A Probability-guided Sampler for Neural Implicit Surface Rendering -
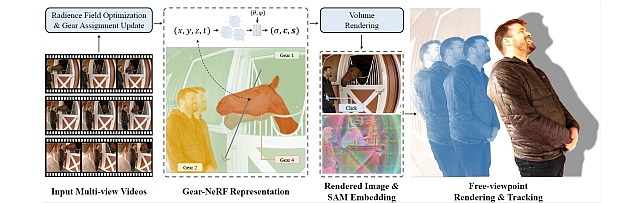
Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-Aware Spatio-Temporal Sampling
-
-
Internships with Moitreya
See All Internships at MERL -
MERL Publications
- , "Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2026.BibTeX TR2026-077 PDF
- @inproceedings{Liu2026jun,
- author = {Liu, Xinhang and Miraldo, Pedro and Lohit, Suhas and Jiang, Huaizu and Sawada, Naoko and Tai, Yu-Wing and Tang, Chi-Keung and Chatterjee, Moitreya},
- title = {{Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-077}
- }
- , "AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2026.BibTeX TR2026-076 PDF Video Data Software
- @inproceedings{Li2026jun,
- author = {Li, Danrui and Zhang, Jiahao and Egger, Bernhard and Chatterjee, Moitreya and Lohit, Suhas and Marks, Tim K. and Cherian, Anoop},
- title = {{AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-076}
- }
- , "LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), May 2026.BibTeX TR2026-055 PDF
- @inproceedings{Ding2026may,
- author = {Ding, Tianye and Xie, Yiming and Liang, Yiqing and Chatterjee, Moitreya and Miraldo, Pedro and Jiang, Huaizu},
- title = {{LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2026,
- month = may,
- url = {https://www.merl.com/publications/TR2026-055}
- }
- , "FreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations", IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR), DOI: 10.1109/CVPRW67362.2025.00041, June 2025, pp. 369-379.BibTeX TR2025-074 PDF
- @inproceedings{Sawada2025jun,
- author = {Sawada, Naoko and Miraldo, Pedro and Lohit, Suhas and Marks, Tim K. and Chatterjee, Moitreya},
- title = {{FreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR)},
- year = 2025,
- pages = {369--379},
- month = jun,
- doi = {10.1109/CVPRW67362.2025.00041},
- url = {https://www.merl.com/publications/TR2025-074}
- }
- , "UWAV: Uncertainty-weighted Weakly-supervised Audio-Visual Video Parsing", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), DOI: 10.1109/CVPR52734.2025.01266, June 2025, pp. 13561-13570.BibTeX TR2025-072 PDF
- @inproceedings{Lai2025jun,
- author = {Lai, Yung-Hsuan and Ebbers, Janek and Wang, Yu-Chiang Frank and Germain, François G and Jones, Michael J. and Chatterjee, Moitreya},
- title = {{UWAV: Uncertainty-weighted Weakly-supervised Audio-Visual Video Parsing}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2025,
- pages = {13561--13570},
- month = jun,
- publisher = {IEEE},
- doi = {10.1109/CVPR52734.2025.01266},
- url = {https://www.merl.com/publications/TR2025-072}
- }
- , "Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2026.
-
Other Publications
- , "A hierarchical variational neural uncertainty model for stochastic video prediction", Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9751-9761.BibTeX
- @Inproceedings{chatterjee2021hierarchical,
- author = {Chatterjee, Moitreya and Ahuja, Narendra and Cherian, Anoop},
- title = {A hierarchical variational neural uncertainty model for stochastic video prediction},
- booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision},
- year = 2021,
- pages = {9751--9761}
- }
- , "Visual scene graphs for audio source separation", Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1204-1213.BibTeX
- @Inproceedings{chatterjee2021visual,
- author = {Chatterjee, Moitreya and Le Roux, Jonathan and Ahuja, Narendra and Cherian, Anoop},
- title = {Visual scene graphs for audio source separation},
- booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision},
- year = 2021,
- pages = {1204--1213}
- }
- , "Dynamic graph representation learning for video dialog via multi-modal shuffled transformers", Proceedings of the AAAI Conference on Artificial Intelligence, 2021, vol. 35, pp. 1415-1423.BibTeX
- @Inproceedings{geng2021dynamic,
- author = {Geng, Shijie and Gao, Peng and Chatterjee, Moitreya and Hori, Chiori and Le Roux, Jonathan and Zhang, Yongfeng and Li, Hongsheng and Cherian, Anoop},
- title = {Dynamic graph representation learning for video dialog via multi-modal shuffled transformers},
- booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence},
- year = 2021,
- volume = 35,
- number = 2,
- pages = {1415--1423}
- }
- , "Sound2sight: Generating visual dynamics from sound and context", European Conference on Computer Vision, 2020, pp. 701-719.BibTeX
- @Inproceedings{chatterjee2020sound2sight,
- author = {Chatterjee, Moitreya and Cherian, Anoop},
- title = {Sound2sight: Generating visual dynamics from sound and context},
- booktitle = {European Conference on Computer Vision},
- year = 2020,
- pages = {701--719},
- organization = {Springer}
- }
- , "Coreset-based neural network compression", Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 454-470.BibTeX
- @Inproceedings{dubey2018coreset,
- author = {Dubey, Abhimanyu and Chatterjee, Moitreya and Ahuja, Narendra},
- title = {Coreset-based neural network compression},
- booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
- year = 2018,
- pages = {454--470}
- }
- , "Deep neural networks with inexact matching for person re-identification", Advances in neural information processing systems, Vol. 29, 2016.BibTeX
- @Article{subramaniam2016deep,
- author = {Subramaniam, Arulkumar and Chatterjee, Moitreya and Mittal, Anurag},
- title = {Deep neural networks with inexact matching for person re-identification},
- journal = {Advances in neural information processing systems},
- year = 2016,
- volume = 29
- }
- , "Combining two perspectives on classifying multimodal data for recognizing speaker traits", Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, 2015, pp. 7-14.BibTeX
- @Inproceedings{chatterjee2015combining,
- author = {Chatterjee, Moitreya and Park, Sunghyun and Morency, Louis-Philippe and Scherer, Stefan},
- title = {Combining two perspectives on classifying multimodal data for recognizing speaker traits},
- booktitle = {Proceedings of the 2015 ACM on International Conference on Multimodal Interaction},
- year = 2015,
- pages = {7--14}
- }
- , "A hierarchical variational neural uncertainty model for stochastic video prediction", Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9751-9761.
-
Software & Data Downloads
-
Videos
-
MERL Issued Patents
-
Title: "NEURAL RADIANCE FIELD TRAINING BASED ON A NON-UNIFORM SAMPLE OF IMAGE PIXELS"
Inventors: Miraldo, Pedro; Greiff, Marcus; Pais, Goncalo; Chatterjee, Moitreya
Patent No.: 12,633,035
Issue Date: May 19, 2026 -
Title: "Rendering Two-Dimensional Image of a Dynamic Three-Dimensional Scene"
Inventors: Chatterjee, Moitreya; Lohit, Suhas; Miraldo, Pedro
Patent No.: 12,475,636
Issue Date: Nov 18, 2025 -
Title: "System and Method for Controlling a Robot"
Inventors: Cherian, Anoop; Chatterjee, Moitreya; Liu, Xiulong; Paul, Sudipta
Patent No.: 12/459/115
Issue Date: Nov 4, 2025 -
Title: "A Method and System for Scene-Aware Audio-Video Representation"
Inventors: Cherian, Anoop; Chatterjee, Moitreya; Le Roux, Jonathan
Patent No.: 12,056,213
Issue Date: Aug 6, 2024
-
Title: "NEURAL RADIANCE FIELD TRAINING BASED ON A NON-UNIFORM SAMPLE OF IMAGE PIXELS"