TR2026-090
Understanding Dynamic Compute Allocation in Recurrent Transformers
-
- , "Understanding Dynamic Compute Allocation in Recurrent Transformers", International Conference on Machine Learning (ICML), July 2026.BibTeX TR2026-090 PDF Software
- @inproceedings{Moosa2026jul,
- author = {Moosa, Ibraheem Muhammad and Lohit, Suhas and Wang, Ye and Chatterjee, Moitreya and Yin, Wenpeng},
- title = {{Understanding Dynamic Compute Allocation in Recurrent Transformers}},
- booktitle = {International Conference on Machine Learning (ICML)},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-090}
- }
- , "Understanding Dynamic Compute Allocation in Recurrent Transformers", International Conference on Machine Learning (ICML), July 2026.
-
MERL Contacts:
-
Research Areas:



Abstract:
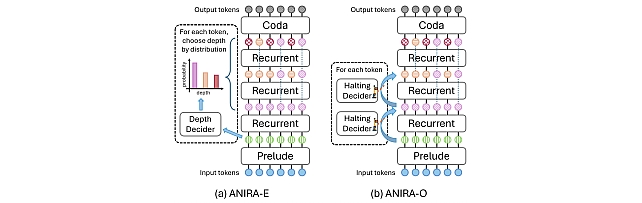
Token-level adaptive computation seeks to reduce inference cost by allocating more computation to harder tokens and less to easier ones. How- ever, prior work is primarily evaluated on natural- language benchmarks using task-level metrics, where token-level difficulty is unobservable and confounded with architectural factors, making it unclear whether compute allocation truly aligns with underlying complexity. We address this gap through three contributions. First, we introduce a complexity-controlled evaluation paradigm using existing algorithmic and synthetic language tasks with parameterized difficulty, enabling direct testing of token-level compute allocation. Second, we propose ANIRA, a unified recur- rent Transformer framework that supports per- token variable-depth computation while isolating compute allocation decisions from other model factors. Third, we use this framework to con- duct a systematic analysis of token-level adaptive computation across alignment with complexity, generalization, and decision timing. Our results show that compute allocation aligned with task complexity can emerge without explicit difficulty supervision, but such alignment does not imply algorithmic generalization: models fail to extrapolate to unseen input sizes despite al- locating additional computation. We further find that early compute decisions rely on static structural cues, whereas online halting more closely tracks algorithmic execution state
Software & Data Downloads
Related Publication
- @article{Moosa2026feb,
- author = {Moosa, Ibraheem Muhammad and Lohit, Suhas and Wang, Ye and Chatterjee, Moitreya and Yin, Wenpeng},
- title = {{Understanding Dynamic Compute Allocation in Recurrent Transformers}},
- journal = {arXiv},
- year = 2026,
- month = feb,
- url = {https://arxiv.org/abs/2602.08864}
- }