LLMPhy: Parameter-Identifiable Physical Reasoning Combining Large Language Models and Physics Engines
A black-box optimization framework that integrates large language models (LLMs) with physics simulators for physical reasoning.
MERL Researchers: Anoop Cherian, Radu Corcodel, Siddarth Jain.
Most learning-based approaches to complex physical reasoning sidestep the crucial problem of parameter identification (e.g., mass, friction) that governs scene dynamics-despite its importance in real-world applications such as collision avoidance and robotic manipulation. We present LLMPhy, a black-box optimization framework that integrates large language models (LLMs) with physics simulators for physical reasoning. The key idea in LLMPhy is to bridge the textbook physical knowledge implicit in LLMs with world models implemented in modern physics engines, thereby enabling the construction of digital twins of input scenes through the estimation of unobservable physics parameters. Specifically, LLMPhy decomposes digital twin construction into two subproblems: a continuous one of estimating physical parameters and a discrete one of estimating scene layout. For each subproblem, LLMPhy iteratively prompts the LLM to generate Python programs embedding parameter estimates, executes them in the physics engine to reconstruct the scene, and then uses the resulting reconstruction error as feedback to refine the LLM's predictions.
As existing physical reasoning benchmarks rarely account for parameter identifiability, we introduce three new datasets: TraySim (a.k.a. LLMPhy TraySim), CLEVRER-LLMPhy, and Real-TraySim, specifically designed to evaluate the physical reasoning capabilities in zero-shot settings. Our results show that LLMPhy achieves state-of-the-art performance on these tasks, recovers physical parameters more accurately, and converges more reliably than popular black-box methods.
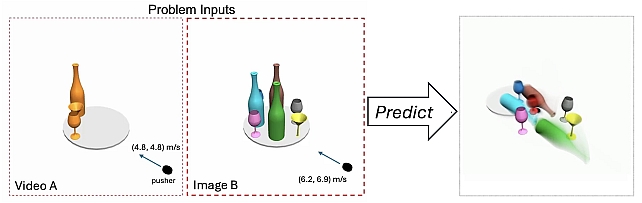
LLMPhy-TraySim Physical Reasoning Task

LLMPhy Architecture
In the LLMPhy architecture, an LLM is prompted with multi-view images and object motion video sequences to synthesize Python code characterizing the underlying physics and object layout. The code is executed in the simulator producing scene reconstructions, which are matched to the inputs producing error. In the next iteration, the LLM is prompted to improvise its estimations to reduce the reconstruction error.
LLMPhy executes in two phases. In phase 1, the unobservable physics parameters of the objects are estimated from the given multi-view video sequences. In phase 2, the scene layout, i.e., where each object is placed in the scene, is estimated from the multi-view input images. The parameters estimated from the two phases are then used to reconstruct the scene shown in the input image in the physics engine, followed by setting the pusher into motion with the given velocity, followed by extracting the steady state of the scene after the impact to select the answers from the given options. LLMPhy uses Python programs for the LLM to interact with the simulator.

Examples from the LLMPhy Datasets
1. LLMPhy TraySim Dataset:

2. CLEVRER-LLMPhy Dataset:


3. Real-Tray-Sim Dataset:
Goal: Predict the trajectory of the box in the test sequence.

Experimental Results


Software & Data Downloads
MERL Publications
- , "LLMPhy: Parameter-Identifiable Physical Reasoning Combining Large Language Models and Physics Engines", International Conference on Artificial Intelligence and Statistics (AISTATS), May 2026.BibTeX TR2026-052 PDF Data Software
- @inproceedings{Cherian2026may,
- author = {Cherian, Anoop and Corcodel, Radu and Jain, Siddarth and Romeres, Diego},
- title = {{LLMPhy: Parameter-Identifiable Physical Reasoning Combining Large Language Models and Physics Engines}},
- booktitle = {International Conference on Artificial Intelligence and Statistics (AISTATS)},
- year = 2026,
- month = may,
- url = {https://www.merl.com/publications/TR2026-052}
- }