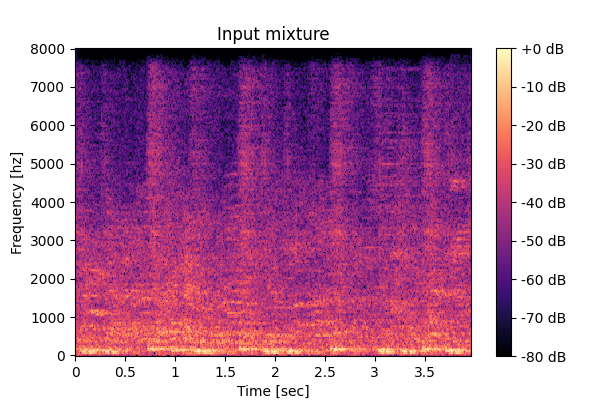
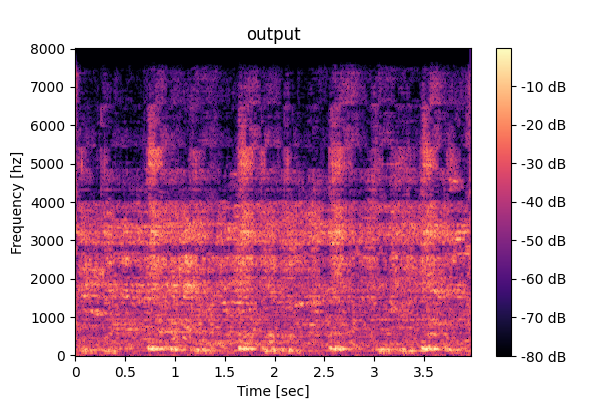
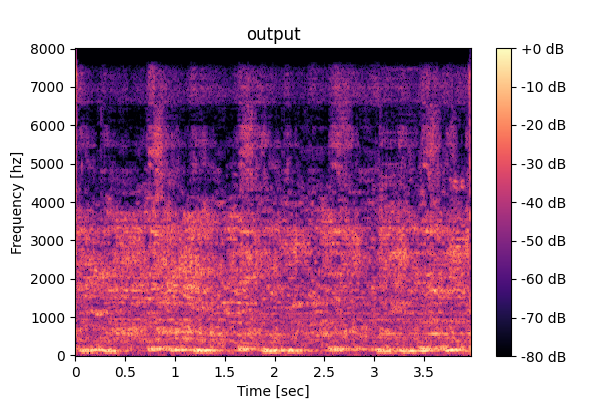
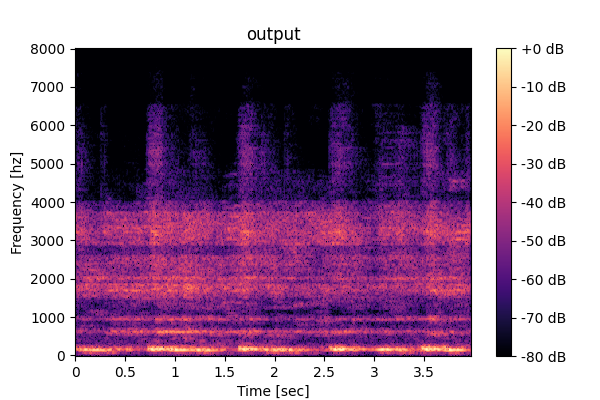
This page provides audio examples for the Task-aware Unified Source Separation (TUSS) model introduced in the paper "Task-aware Unified Source Separation",
by Kohei Saijo, Janek Ebbers, François G. Germain, Gordon Wichern, and Jonathan Le Roux, presented at the
IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2025 (TR2025-032).
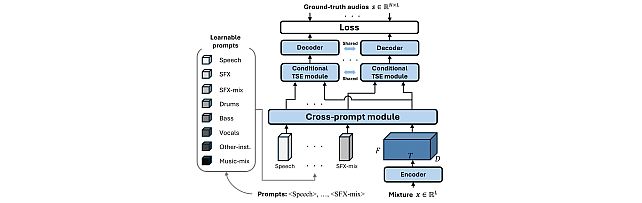
As shown in Fig.1, the model features learnable prompts to specify what source to separate and changes its behavior based on the prompts.
The audio examples include both synthetic mixtures and real recordings.
We provide the audio examples of the following configurations (for some tasks, we skip the specialist model).
We utilized the medium model and M* corresponds to the ID in Table III of the paper.
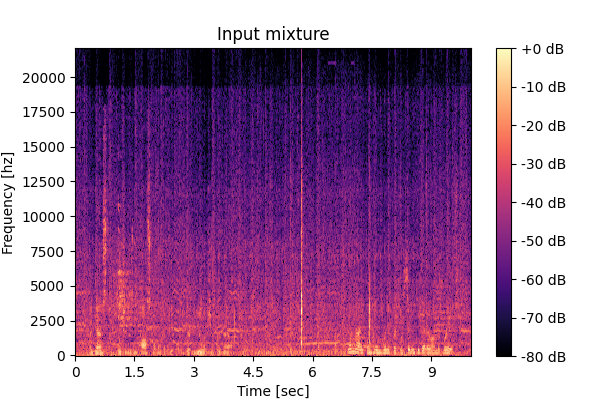
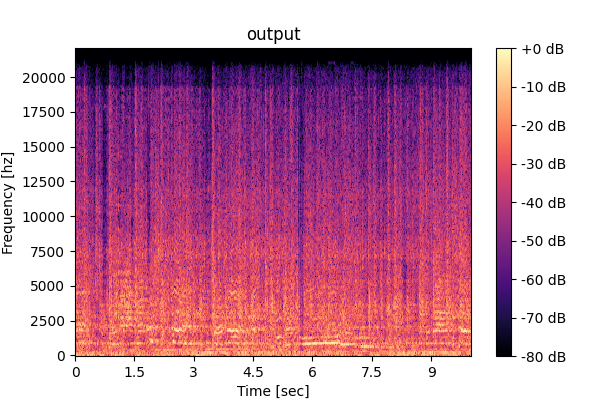
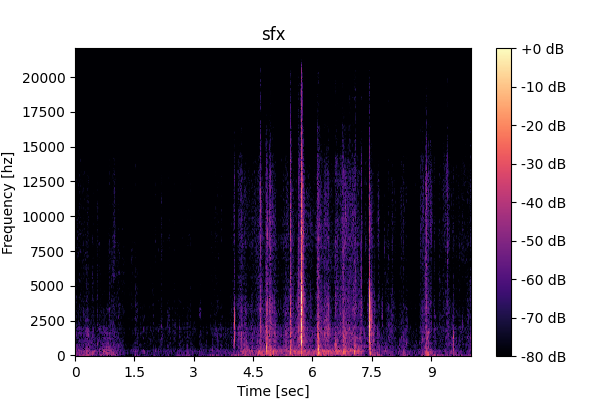
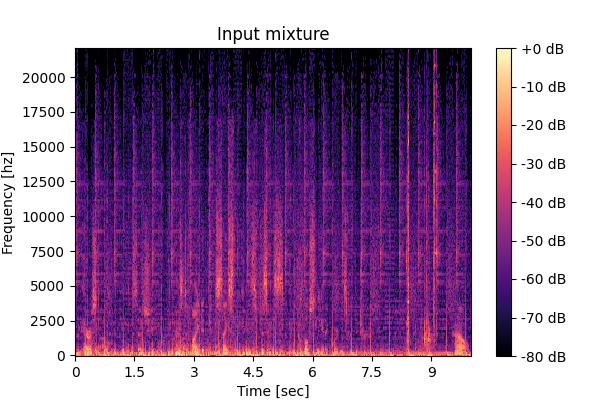
Mixture: Input mixture.
Conventional (task-)specialist model (M2): Unlike the TUSS model, the model does not
have any prompts. A model is trained specifically for each given task by utilizing only the data for that task
and configuring the model to have the same number of output channels as that of sources in the mixtures.
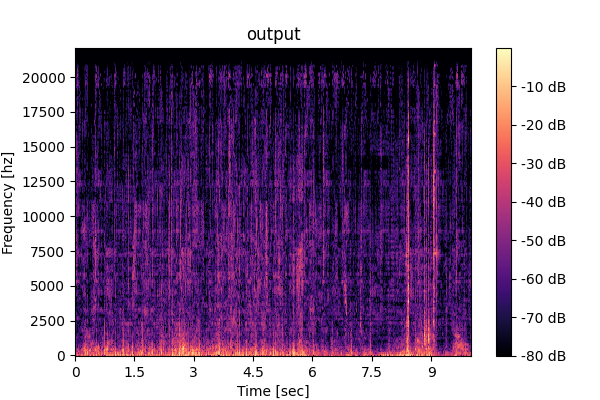
Conventional unified model (M4): The network architecture is almost the same as the
conventional specialist, but the model always outputs 4 sources. The model is trained on all the datasets
for all the tasks, and is trained to output zeros when the number of sources is fewer than 4.
Prompting unified model(M5): Proposed TUSS model. It receives several prompts and
outputs the specified sources. The number of outputs is the same as that of prompts. Note that the model was only trained with up to 4 prompts, yet some of the examples below show successful separation with 5 prompts.
DnR is a dataset for the cinematic audio source separation (CASS) task. Each mixture includes speech, mixture of musical instruments (Music-mix), and mixture of sound effects (SFXs).
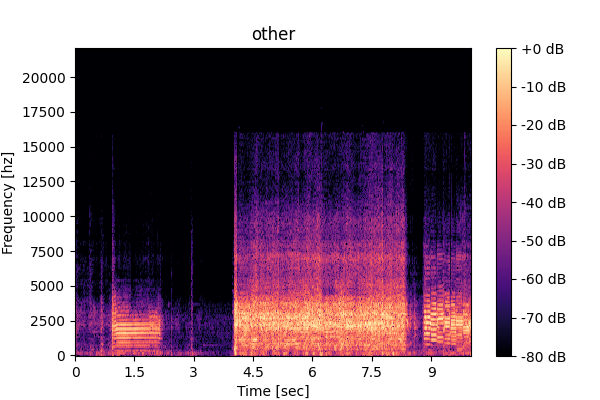
In this example, Music-mix includes vocals and other instruments.
By changing the prompts, we can specify whether to separate musical intruments or SFXs into each source.
For the TUSS model, we consider 4 combinations of prompts and show how well the model changes its behavior just by changing the prompts.
Mixture
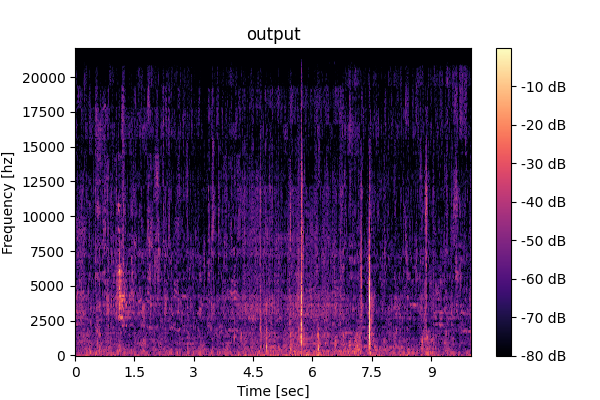
Conventional unified model (M4)
Output1
Output2
Output3
Output4
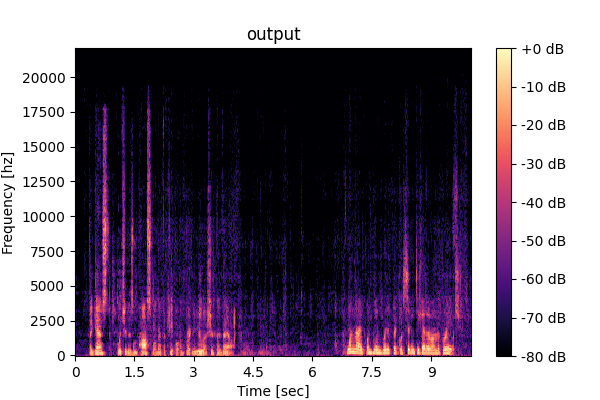
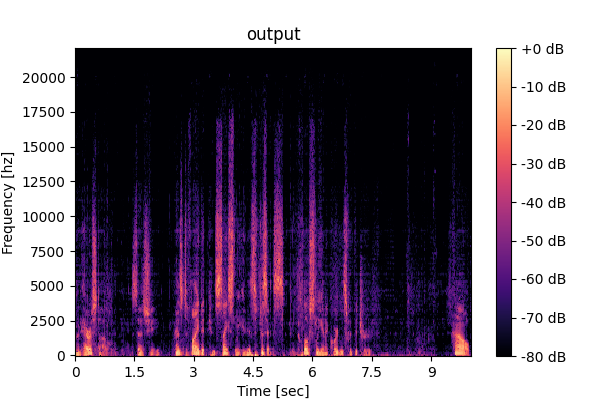
Prompting unified model (M5): <Speech>, <Music-mix>, <SFX-mix>
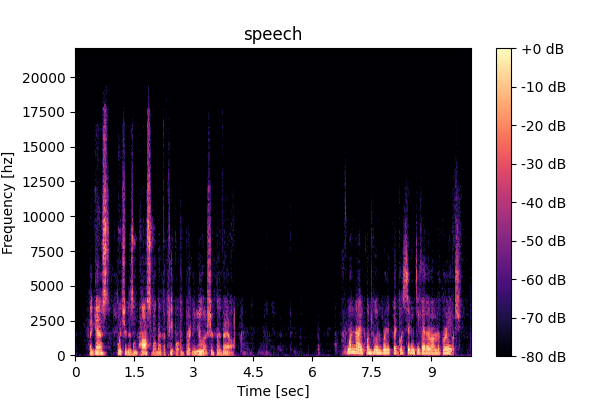
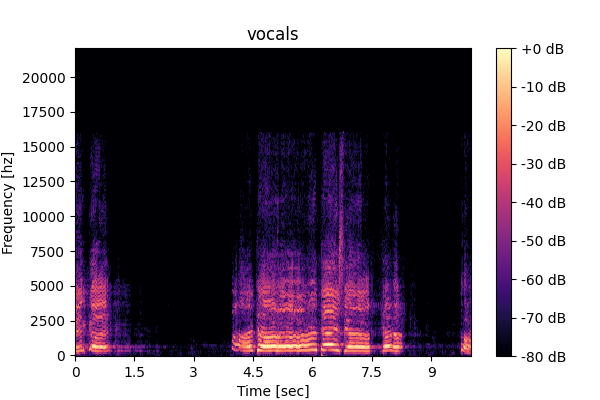
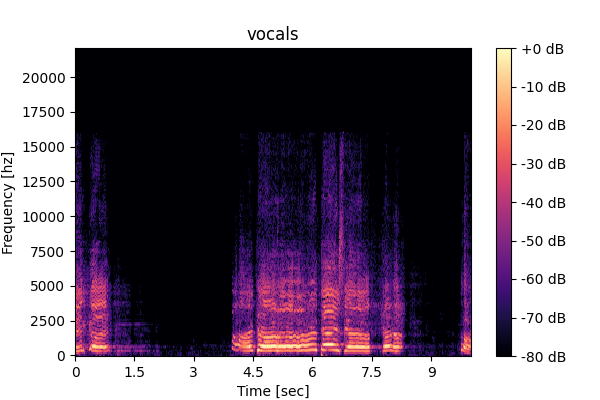
Speech
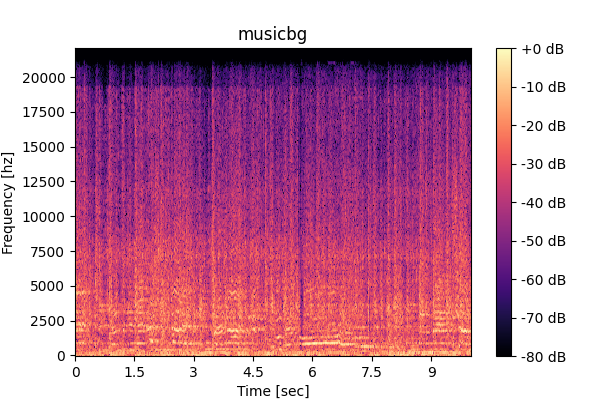
Music-mix
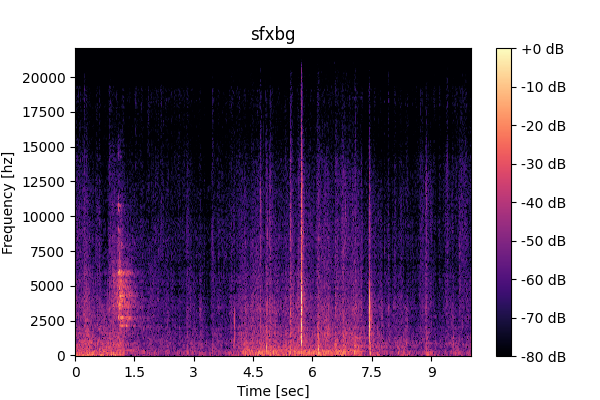
SFX-mix
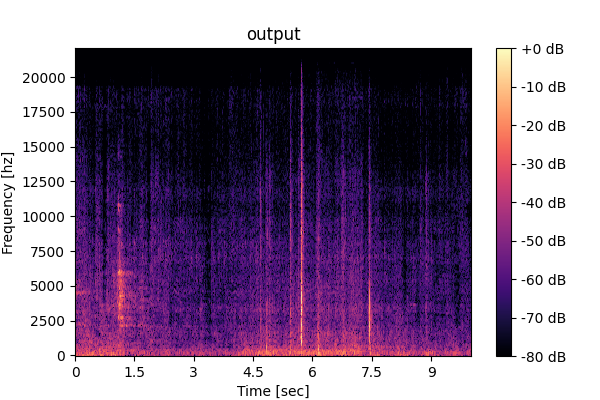
Prompting unified model (M5): <Speech>, <Vocals>, <Other inst.>, <SFX-mix>
Speech
Vocals
Other inst.
SFX-mix
Prompting unified model (M5): <Speech>, <Music-mix>, <SFX>, <SFX>
Speech
Music-mix
SFX
SFX
Prompting unified model (M5): <Speech>, <Vocals>, <Other inst.>, <SFX>,
<SFX>
DnR is a dataset for the cinematic audio source separation (CASS) task.
Each mixture includes speech, mixture of musical instruments (Music-mix), and mixture of sound effects
(SFXs).
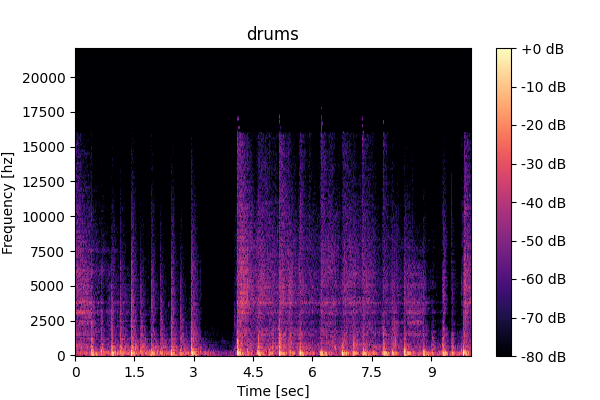
In this example, Music-mix includes drums and other instruments.
By changing the prompts, we can specify whether to separate musical intruments or SFXs into each
source.
For the TUSS model, we consider 4 combinations of prompts and show how well the model changes its
behavior just by changing the prompts.
Note that this example was purposely chosen from the training set of DnR to see if the data trained
not to be separated can also be separated by changing the prompts.
Specifically, the Free Music Archive (FMA) dataset used as the Music-mix in DnR is always used only as a
Music-mix for the model training, and thus the model is not trained to separate the FMA data set.
Although both the conventional model and the proposed model separate the mixture very well into Speech,
Music-mix, and SFX-mix, the proposed TUSS model can also separate Music-mix or SFX-mix further into multiple sources. We note some hi-hat leakage in the "Other inst." output: "Other inst." is a "catch-all" category in the original datasets, which makes the model likely to be more inclusive (SOTA MSS models in fact found it better not to directly separate it, and instead obtain it as a residual from the remaining classes).
Mixture
Conventional unified model (M4)
Output1
Output2
Output3
Output4
Prompting unified model (M5): <Speech>, <Music-mix>, <SFX-mix>
Speech
Music-mix
SFX-mix
Prompting unified model (M5): <Speech>, <Music-mix>, <SFX>, <SFX>
Speech
Music-mix
SFX
SFX
Prompting unified model (M5): <Speech>, <Drums>, <Other Inst.>, <SFX-mix>
Speech
Drums
Other inst.
SFX-mix
Prompting unified model (M5): <Speech>, <Drums>, <Other Inst.>, <SFX>,
<SFX>
Each data in Free Music Archive (FMA) includes a mixture of musical instruments. In this example, the
mixture has bass, drums, vocals, and other instruments.
FMA is used as MUSIC-mix data for training since it does not have any ground-truth audio.
This example demonstrates that it is challenging for the conventional unified model to separate FMA data,
possibly because the model overfits to FMA data as a source that is not to be separated.
The proposed model is trained in the same manner but it can successfully separate all the sources given the right prompts.
We also provide the outputs from the specialist model trained only on MUSDB and MoisesDB.
In the last example, we feed the combination of prompts [<Vocals>, <Music-mix>], which was unseen during training.
While Vocals is extracted well, the output for Music-mix is almost the same as the input mixture. This is in fact expected since we train the model to output the mixture of musical instruments when given <Music-mix>.
This example demonstrates that the model (i) works even with unseen combinations of prompts and
(ii) does not constrain the output sources to add up to the input mixture.
Mixture
Conventional specialist model (M2)
Output1
Output2
Output3
Output4
Conventional unified model (M4)
Output1
Output2
Output3
Output4
Prompting unified model (M5): <Bass>, <Drums>, <Vocals>, <Other Inst.>
Bass
Drums
Vocals
Other inst.
Prompting unified model (M5): <Vocals>, <Music-mix>
WHAM! is a real-recorded noise dataset and was always used as SFX-mix data since it does
not have any ground-truth audio. Some of the samples include background speech and we see here if the model can extract it.
Similar to the example of FMA, the conventional model is likely to overfit to WHAM! noise as a single
source that is not to be separated. It works to some extent but does not separate Speech and SFX very well.
However, the proposed model does separate Speech and SFX very well.
WHAM! is a real-recorded noise dataset and was always used as SFX-mix data since it does
not have any ground-truth audio. Some of the samples include musical instruments and we see here if the model can extract them.
Similar to the example of FMA, the conventional model is likely to overfit to WHAM! noise as a single
source that is not to be separated. It works to some extent but does not separate Drums and SFX very well.
However, the proposed model does separate Drums and SFX very well.