TR2022-131
AVLEN: Audio-Visual-Language Embodied Navigation in 3D Environments
-
- , "AVLEN: Audio-Visual-Language Embodied Navigation in 3D Environments", Advances in Neural Information Processing Systems (NeurIPS), October 2022, pp. 6236-6249.BibTeX TR2022-131 PDF Video Data Software
- @inproceedings{Paul2022oct2,
- author = {Paul, Sudipta and Roy Chowdhury, Amit K and Cherian, Anoop},
- title = {{AVLEN: Audio-Visual-Language Embodied Navigation in 3D Environments}},
- booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
- year = 2022,
- pages = {6236--6249},
- month = oct,
- url = {https://www.merl.com/publications/TR2022-131}
- }
- , "AVLEN: Audio-Visual-Language Embodied Navigation in 3D Environments", Advances in Neural Information Processing Systems (NeurIPS), October 2022, pp. 6236-6249.
-
MERL Contact:
-
Research Areas:
Artificial Intelligence, Computer Vision, Machine Learning, Speech & Audio

Abstract:
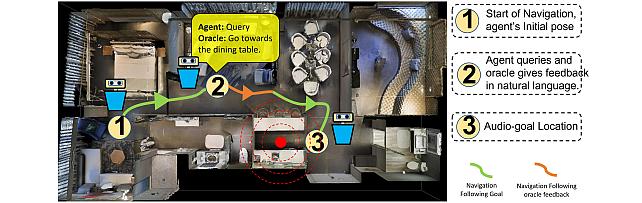
Recent years have seen embodied visual navigation advance in two distinct directions: (i) in equipping the AI agent to follow natural language instructions, and (ii) in making the navigable world multimodal, e.g., audio-visual navigation. However, the real world is not only multimodal, but also often complex, and thus in spite of these advances, agents still need to understand the uncertainty in their actions and seek instructions to navigate. To this end, we present AVLEN – an interactive agent for Audio-Visual-Language Embodied Navigation. Similar to audio-visual navigation tasks, the goal of our embodied agent is to localize an audio event via navigating the 3D visual world; however, the agent may also seek help from a human (oracle), where the assistance is provided in free-form natural language. To realize these abilities, AVLEN uses a multimodal hierarchical reinforcement learning backbone that learns: (a) high-level policies to choose either audio-cues for navigation or to query the oracle, and (b) lower-level policies to select navigation actions based on its audio-visual and language inputs. The policies are trained via rewarding for the success on the navigation task while minimizing the number of queries to the oracle. To empirically evaluate AVLEN, we present experiments on the SoundSpaces framework for semantic audio-visual navigation tasks. Our results show that equipping the agent to ask for help leads to a clear improvement in performance, especially in challenging cases, e.g., when the sound is unheard during training or in the presence of distractor sounds.
Software & Data Downloads
Related News & Events
-
NEWS MERL researchers presenting five papers at NeurIPS 2022 Date: November 29, 2022 - December 9, 2022
Where: NeurIPS 2022
MERL Contacts: Moitreya Chatterjee; Anoop Cherian; Michael J. Jones; Suhas Lohit
Research Areas: Artificial Intelligence, Computer Vision, Machine Learning, Speech & AudioBrief- MERL researchers are presenting 5 papers at the NeurIPS Conference, which will be held in New Orleans from Nov 29-Dec 1st, with virtual presentations in the following week. NeurIPS is one of the most prestigious and competitive international conferences in machine learning.
MERL papers in NeurIPS 2022:
1. “AVLEN: Audio-Visual-Language Embodied Navigation in 3D Environments” by Sudipta Paul, Amit Roy-Chowdhary, and Anoop Cherian
This work proposes a unified multimodal task for audio-visual embodied navigation where the navigating agent can also interact and seek help from a human/oracle in natural language when it is uncertain of its navigation actions. We propose a multimodal deep hierarchical reinforcement learning framework for solving this challenging task that allows the agent to learn when to seek help and how to use the language instructions. AVLEN agents can interact anywhere in the 3D navigation space and demonstrate state-of-the-art performances when the audio-goal is sporadic or when distractor sounds are present.
2. “Learning Partial Equivariances From Data” by David W. Romero and Suhas Lohit
Group equivariance serves as a good prior improving data efficiency and generalization for deep neural networks, especially in settings with data or memory constraints. However, if the symmetry groups are misspecified, equivariance can be overly restrictive and lead to bad performance. This paper shows how to build partial group convolutional neural networks that learn to adapt the equivariance levels at each layer that are suitable for the task at hand directly from data. This improves performance while retaining equivariance properties approximately.
3. “Learning Audio-Visual Dynamics Using Scene Graphs for Audio Source Separation” by Moitreya Chatterjee, Narendra Ahuja, and Anoop Cherian
There often exist strong correlations between the 3D motion dynamics of a sounding source and its sound being heard, especially when the source is moving towards or away from the microphone. In this paper, we propose an audio-visual scene-graph that learns and leverages such correlations for improved visually-guided audio separation from an audio mixture, while also allowing predicting the direction of motion of the sound source.
4. “What Makes a "Good" Data Augmentation in Knowledge Distillation - A Statistical Perspective” by Huan Wang, Suhas Lohit, Michael Jones, and Yun Fu
This paper presents theoretical and practical results for understanding what makes a particular data augmentation technique (DA) suitable for knowledge distillation (KD). We design a simple metric that works very well in practice to predict the effectiveness of DA for KD. Based on this metric, we also propose a new data augmentation technique that outperforms other methods for knowledge distillation in image recognition networks.
5. “FeLMi : Few shot Learning with hard Mixup” by Aniket Roy, Anshul Shah, Ketul Shah, Prithviraj Dhar, Anoop Cherian, and Rama Chellappa
Learning from only a few examples is a fundamental challenge in machine learning. Recent approaches show benefits by learning a feature extractor on the abundant and labeled base examples and transferring these to the fewer novel examples. However, the latter stage is often prone to overfitting due to the small size of few-shot datasets. In this paper, we propose a novel uncertainty-based criteria to synthetically produce “hard” and useful data by mixing up real data samples. Our approach leads to state-of-the-art results on various computer vision few-shot benchmarks.
- MERL researchers are presenting 5 papers at the NeurIPS Conference, which will be held in New Orleans from Nov 29-Dec 1st, with virtual presentations in the following week. NeurIPS is one of the most prestigious and competitive international conferences in machine learning.