TR2021-095
Visual Scene Graphs for Audio Source Separation
-
- , "Visual Scene Graphs for Audio Source Separation", IEEE International Conference on Computer Vision (ICCV), October 2021, pp. 1204-1213.BibTeX TR2021-095 PDF Video Software
- @inproceedings{Chatterjee2021oct,
- author = {Chatterjee, Moitreya and {Le Roux}, Jonathan and Ahuja, Narendra and Cherian, Anoop},
- title = {{Visual Scene Graphs for Audio Source Separation}},
- booktitle = {IEEE International Conference on Computer Vision (ICCV)},
- year = 2021,
- pages = {1204--1213},
- month = oct,
- publisher = {CVF},
- url = {https://www.merl.com/publications/TR2021-095}
- }
- , "Visual Scene Graphs for Audio Source Separation", IEEE International Conference on Computer Vision (ICCV), October 2021, pp. 1204-1213.
-
MERL Contacts:
-
Research Areas:
Artificial Intelligence, Computer Vision, Machine Learning, Speech & Audio



Abstract:
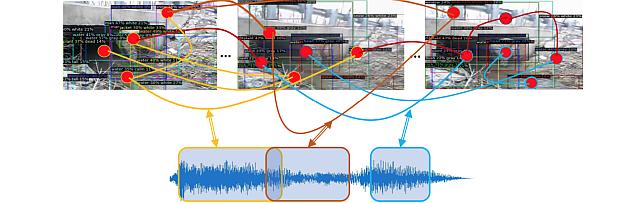
State-of-the-art approaches for visually-guided audio source separation typically assume sources that have characteristic sounds, such as musical instruments. These approaches often ignore the visual context of these sound sources or avoid modeling object interactions that may be useful to characterize the sources better, especially when the same object class may produce varied sounds from distinct interactions. To address this challenging problem, we propose Audio Visual Scene Graph Segmenter ~(AVSGS), a novel deep learning model that embeds the visual structure of the scene as a graph and segments this graph into subgraphs, each subgraph being associated with a unique sound obtained via co-segmenting the audio spectrogram. At its core, AVSGS uses a recursive neural network that emits mutually-orthogonal sub-graph embeddings of the visual graph using multi-head attention, these embeddings conditioning an audio encoder-decoder towards source separation. Our pipeline is trained end-to-end via a self-supervision task that consists in separating audio sources using the visual graph from artificially mixed sounds.
In this paper, we also introduce an “in the wild” dataset for sound source separation that contains multiple non-musical sources, which we call Audio Separation in the Wild~(ASIW). This dataset is adapted from the AudioCaps dataset, and provides a challenging natural and daily-life setting for source separation. Thorough experiments on the proposed ASIW and the standard MUSIC datasets demonstrate state-of-the-art sound separation performances of our method against recent prior approaches.
Software & Data Downloads
Related Video
Related Publication
- @article{Chatterjee2021dec,
- author = {Chatterjee, Moitreya and {Le Roux}, Jonathan and Ahuja, Narendra and Cherian, Anoop},
- title = {{Visual Scene Graphs for Audio Source Separation}},
- journal = {arXiv},
- year = 2021,
- volume = {abs/2109.11955},
- month = dec,
- url = {https://arxiv.org/abs/2109.11955}
- }