TR2024-126
TF-Locoformer: Transformer with Local Modeling by Convolution for Speech Separation and Enhancement
-
- , "TF-Locoformer: Transformer with Local Modeling by Convolution for Speech Separation and Enhancement", International Workshop on Acoustic Signal Enhancement (IWAENC), DOI: 10.1109/IWAENC61483.2024.10694313, September 2024, pp. 205-209.BibTeX TR2024-126 PDF Software
- @inproceedings{Saijo2024sep2,
- author = {Saijo, Kohei and Wichern, Gordon and Germain, François G and Pan, Zexu and {Le Roux}, Jonathan},
- title = {{TF-Locoformer: Transformer with Local Modeling by Convolution for Speech Separation and Enhancement}},
- booktitle = {International Workshop on Acoustic Signal Enhancement (IWAENC)},
- year = 2024,
- pages = {205--209},
- month = sep,
- doi = {10.1109/IWAENC61483.2024.10694313},
- issn = {2835-3439},
- isbn = {979-8-3503-6185-8},
- url = {https://www.merl.com/publications/TR2024-126}
- }
- , "TF-Locoformer: Transformer with Local Modeling by Convolution for Speech Separation and Enhancement", International Workshop on Acoustic Signal Enhancement (IWAENC), DOI: 10.1109/IWAENC61483.2024.10694313, September 2024, pp. 205-209.
-
MERL Contacts:
-
Research Areas:


Abstract:
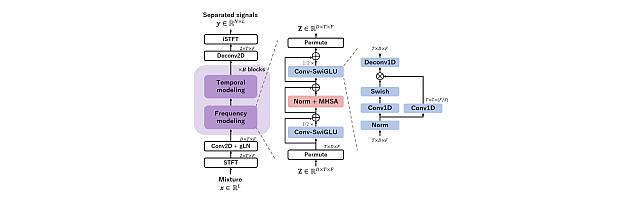
Time-frequency (TF) domain dual-path models achieve high-fidelity speech separation. While some previous state-of-the-art (SoTA) models rely on RNNs, this reliance means they lack the parallelizability, scalability, and versatility of Transformer blocks. Given the wide-ranging success of pure Transformer-based architectures in other fields, in this work we focus on removing the RNN from TF-domain dual-path models, while maintaining SoTA performance. This work presents TF-Locoformer, a Transformer-based model with LOcal-modeling by COnvolution. The model uses feed- forward networks (FFNs) with convolution layers, instead of linear layers, to capture local information, letting the self-attention focus on capturing global patterns. We place two such FFNs before and after self-attention to enhance the local-modeling capability. We also introduce a novel normalization for TF-domain dual-path models. Experiments on separation and enhancement datasets show that the proposed model meets or exceeds SoTA in multiple benchmarks with an RNN-free architecture.
Software & Data Downloads
Related Publication
- @article{Saijo2024aug2,
- author = {Saijo, Kohei and Wichern, Gordon and Germain, François G and Pan, Zexu and {Le Roux}, Jonathan},
- title = {{TF-Locoformer: Transformer with Local Modeling by Convolution for Speech Separation and Enhancement}},
- journal = {arXiv},
- year = 2024,
- month = aug,
- url = {https://www.arxiv.org/abs/2408.03440}
- }