AWARD Joint CMU-MERL team wins DCASE2023 Challenge on Automated Audio Captioning
Date released: June 20, 2023
-
AWARD Joint CMU-MERL team wins DCASE2023 Challenge on Automated Audio Captioning Date:
June 1, 2023
Awarded to:
Shih-Lun Wu, Xuankai Chang, Gordon Wichern, Jee-weon Jung, Francois Germain, Jonathan Le Roux, Shinji Watanabe
-
Description:
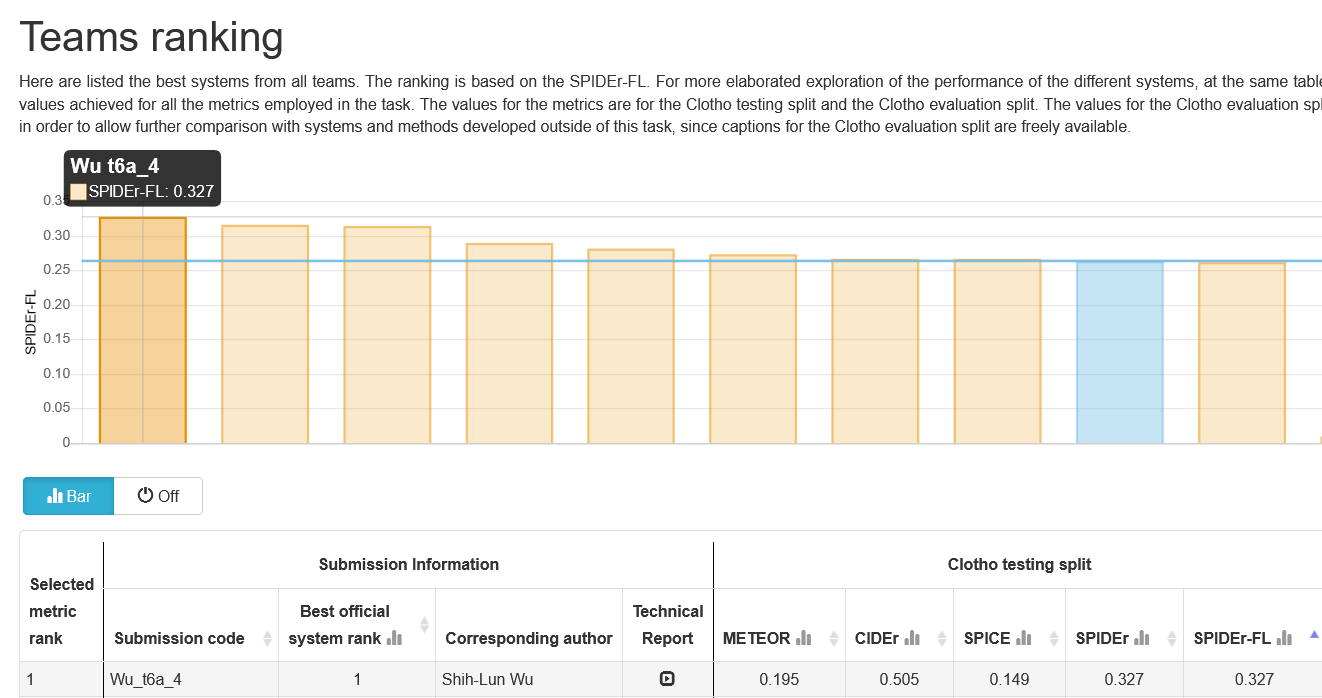
A joint team consisting of members of CMU Professor and MERL Alumn Shinji Watanabe's WavLab and members of MERL's Speech & Audio team ranked 1st out of 11 teams in the DCASE2023 Challenge's Task 6A "Automated Audio Captioning". The team was led by student Shih-Lun Wu and also featured Ph.D. candidate Xuankai Chang, Postdoctoral research associate Jee-weon Jung, Prof. Shinji Watanabe, and MERL researchers Gordon Wichern, Francois Germain, and Jonathan Le Roux.
The IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge), started in 2013, has been organized yearly since 2016, and gathers challenges on multiple tasks related to the detection, analysis, and generation of sound events. This year, the DCASE2023 Challenge received over 428 submissions from 123 teams across seven tasks.
The CMU-MERL team competed in the Task 6A track, Automated Audio Captioning, which aims at generating informative descriptions for various sounds from nature and/or human activities. The team's system made strong use of large pretrained models, namely a BEATs transformer as part of the audio encoder stack, an Instructor Transformer encoding ground-truth captions to derive an audio-text contrastive loss on the audio encoder, and ChatGPT to produce caption mix-ups (i.e., grammatical and compact combinations of two captions) which, together with the corresponding audio mixtures, increase not only the amount but also the complexity and diversity of the training data. The team's best submission obtained a SPIDEr-FL score of 0.327 on the hidden test set, largely outperforming the 2nd best team's 0.315. -
MERL Contacts:
-
External Link:
https://dcase.community/challenge2023/task-automated-audio-captioning-results
-
Research Areas:
-
Related Publications
- , "BEATs-based Audio Captioning Model with Instructor Embedding Supervision and ChatGPT Mix-up," Tech. Rep. TR2023-068, DCASE2023 Challenge, May 2023.
BibTeX TR2023-068 PDF- @techreport{Wu2023may,
- author = {Wu, Shih-Lun and Chang, Xuankai and Wichern, Gordon and Jung, Jee-weon and Germain, Francois and {Le Roux}, Jonathan and Watanabe, Shinji},
- title = {{BEATs-based Audio Captioning Model with Instructor Embedding Supervision and ChatGPT Mix-up}},
- institution = {DCASE2023 Challenge},
- year = 2023,
- month = may,
- url = {https://www.merl.com/publications/TR2023-068}
- }
- , "BEATs-based Audio Captioning Model with Instructor Embedding Supervision and ChatGPT Mix-up," Tech. Rep. TR2023-068, DCASE2023 Challenge, May 2023.
-

